
目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
4.数据库拆分和一致性哈希
5.分布式文件系统
6.分布式数据存储系统
7.聊天系统
8.打车系统
9.分布式计算和爬虫系统
问题:搜索引擎自动补全功能typeahead/google suggest
1.明确设计需求
搜索引擎建议功能的后端实现
当用户输入一段想要搜索内容的前缀时,返回可能匹配的Top10结果
假设月活跃用户有500M,每人每天搜索6次,平均一次输入10个字符
QPS = 500M * 6 * 10 / 86400 ~ 350k
峰值QPS = 350k * 3 ~ 1M
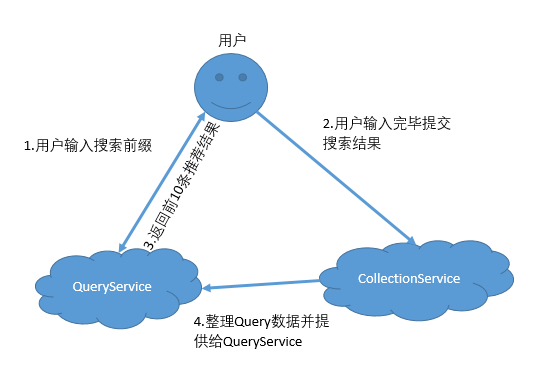
2.设计服务
主要有两个服务
- QueryService 负责提供Top10的查询
- CollectionService 负责统计用户查询过的内容并提供给QueryService
3.存储结构设计
CollectionService
CollectionService负责收集每个Query被搜索的次数
key: query
value: 被搜索的次数
QueryService
对于QueryService,要进行前缀查询,最好的数据结构是Trie,前缀树。但是没有现成的支持该结构的数据库。
需要使用key-value型的数据库进行替代。
key: 前缀
value: Top10查询结果
更新方式:
定期遍历所有query
- 如果apple被搜索了一亿次
- apple需要加入到a, ap, app, appl, apple这5个前缀的查询结果中
- 如果要加入的前缀的Top10搜索次数都比新加入的多,那么就不需要加入到这个结果中了
- 这个过程可以使用MapReduce来优化效率
相当于存储内容如下
- a: [‘amazon’, ‘apple’, ‘airbnb’, ‘aws’, ‘a站’, …]
- ap: [‘apex’, ‘april’, ‘apple’, ‘apple id’, ‘apple watch’, …]
- app: [‘app开发’, ‘apple官网’, ‘apple id’, ‘apple care’, ‘apple’, …]
- …
4.拓展系统
如何优化CollectionService
并不是每条Query都会成为Top10, 这样就会浪费大量存储空间。
解决方案:
不需要记录准确的Query数量,只需要一个相对的名次即可。
对所有query记录添加一列random数字(例如1~10000), 只对value=1的内容进行统计,其他删除。
这样就获得了一个相对准确的Top10, 存储的内容大大减少。
用户输入的速度很快
这个时候没有必要按每个字或者字母都发出一次查询请求,比如用户想搜索apple,他并不关心app会返回什么结果。
解决方案:
1.在前端设置延时,当用户停止输入超过一段时间(例如200ms)后,才发送请求。
2.使用前后端缓存和预加载优化查询效率(推荐)
- 前端缓存: 可以使用local storage缓存用户曾经输入过的内容和对应的Top10, 也可以设置过期时间防止内容过时。(PS: 打开自己的浏览器,可以看到在acwing上面提交过的代码也会存在local storage里面)
- 后端缓存:每次更新Top10的时候,同步更新后端的缓存。
- 预加载:提前返回一些用户极有可能需要的内容。比如用户搜索ap, 那么他很有可能搜索app, apple,apex等等,这个时候就可以假设用户会输入这些内容,并返回给前端提前缓存起来。这样虽然会增加后端内部的查询次数,但是会减少前后端之间的通讯次数。而后端系统内部的查询速度要远快于前后端之间的通信,所以这个优化是值得。
如何获得实时热门
构建一套一模一样的系统,查询内容换成最近2小时内的热门搜索,2个小时更新一次数据。
用户的查询请求需要汇总两种查询结果,汇总的时候可以用一些算法来提高热门搜索的权重。
