
目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
Cassandra
结构
包含三层,row_key, column_key, value
Cassandra的key = row_key + column_key,同一个key只对应一个value
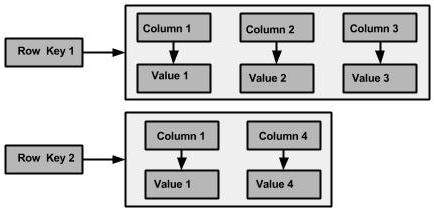
row_key
又叫Hash key,数据库根据row_key计算一个hash值,然后决定整条数据存储位置,不支持范围查询,适合用来记录user_id
column_key
一般用来指定按照什么顺序来进行查询,支持范围查询(例如column_key保存时间相关的信息)
常用的两个操作:
- insert(row_key, column_key, value)
- query(row_key, column_start, column_end)
Friendship Service
好友关系
- 单向好友关系(可以单方面关注,不需要对方确认)
- 双向好友关系(关注并确认后,双方互为好友关系)
保存在SQL数据库中
数据结构
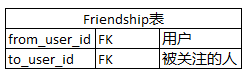
- 查询某人所有关注对象
select * from friendship where from_user_id=x- 查询某人所有粉丝
select * from friendship where to_user_id=x
保存在NoSQL数据库中
数据结构
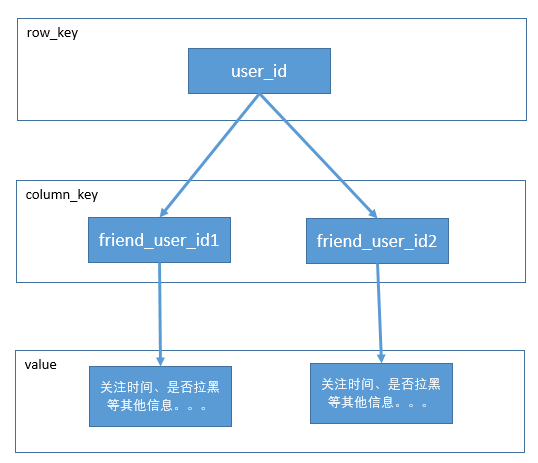
SQL vs NoSQL
- 大部分情况下,用哪种数据库都是可以的
- 如果对数据库的事务有要求的话一般选择SQL,高版本的Mongodb也是支持事务的
- 用于结构化的数据,需要支持索引,选择SQL。而NoSQL适合分布式,replica
- 对于User表,一般使用SQL,而对于Friendship表,一般使用NoSQL,数据简单,效率更高
共同好友
- 获取A的好友列表
- 获取B的好友列表
- 求交集
优化:将好友列表的查询结果缓存起来
六度好友关系
六度关系理论: 最多通过六个人你就能够认识任何一个陌生人。
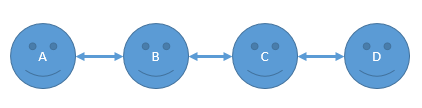
- A和B之间是一度关系
- A和C之间是二度关系
- A和D之间是三度关系
- 一般来说,三度以上关系是没有现实意义的,可以直接显示3+
求A和C之间是几度好友关系
不能使用BFS来进行计算,假设每个人有1000个好友的话,二度关系的计算数量就可以到达百万级别,对于一个线上系统来说是没办法接受这个数量级的计算,时间复杂度应该控制到有限次数O(1)。
实际可以通过离线处理,提前算好所有的一度二度关系并保存在NoSQL中。
查询A的一度(直接好友)关系得到一个集合1
查询C的一度关系得到集合2
如果集合1和集合2有交集,则A和C为一度好友关系
查询A的二度(间接好友)关系得到一个集合3
如果集合1和集合3有交集,则A和C为二度好友关系
如果没有交集则为3度以上好友关系
这样对于一个请求只需要最多3次查询就可以得到结果。

正在学习系统设计相关的,大佬写的非常好。