
目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
4.数据库拆分和一致性哈希
5.分布式文件系统
6.分布式数据存储系统
7.聊天系统
8.打车系统
搜索引擎系统
前置内容
a.分布式计算 Map Reduce
怎么样统计一个词出现在文章中的次数
最简单的方法是哈希表加for循环,但是只能用一台机器,而且受到内存大小的限制
Map Reduce
MapReduce框架一般分为以下几个步骤:
- 输入
- 拆分输入
- 映射(Map)
- 传输整理
- 归约(Reduce)
- 输出
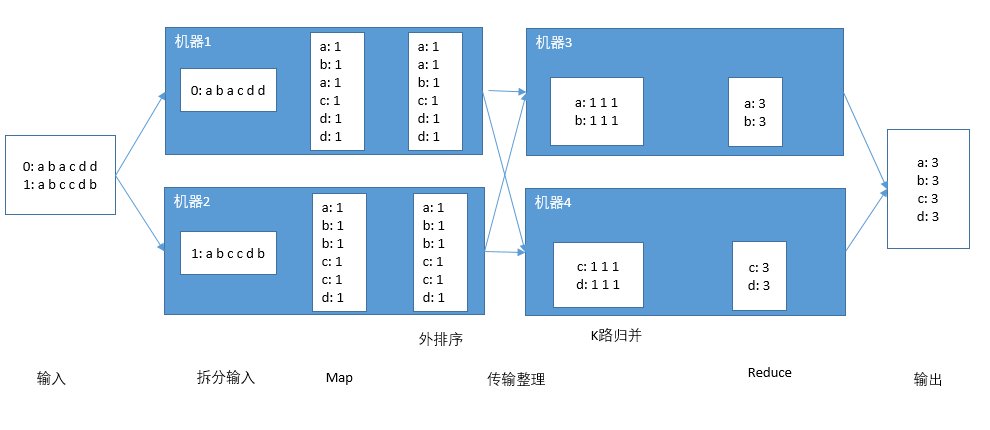
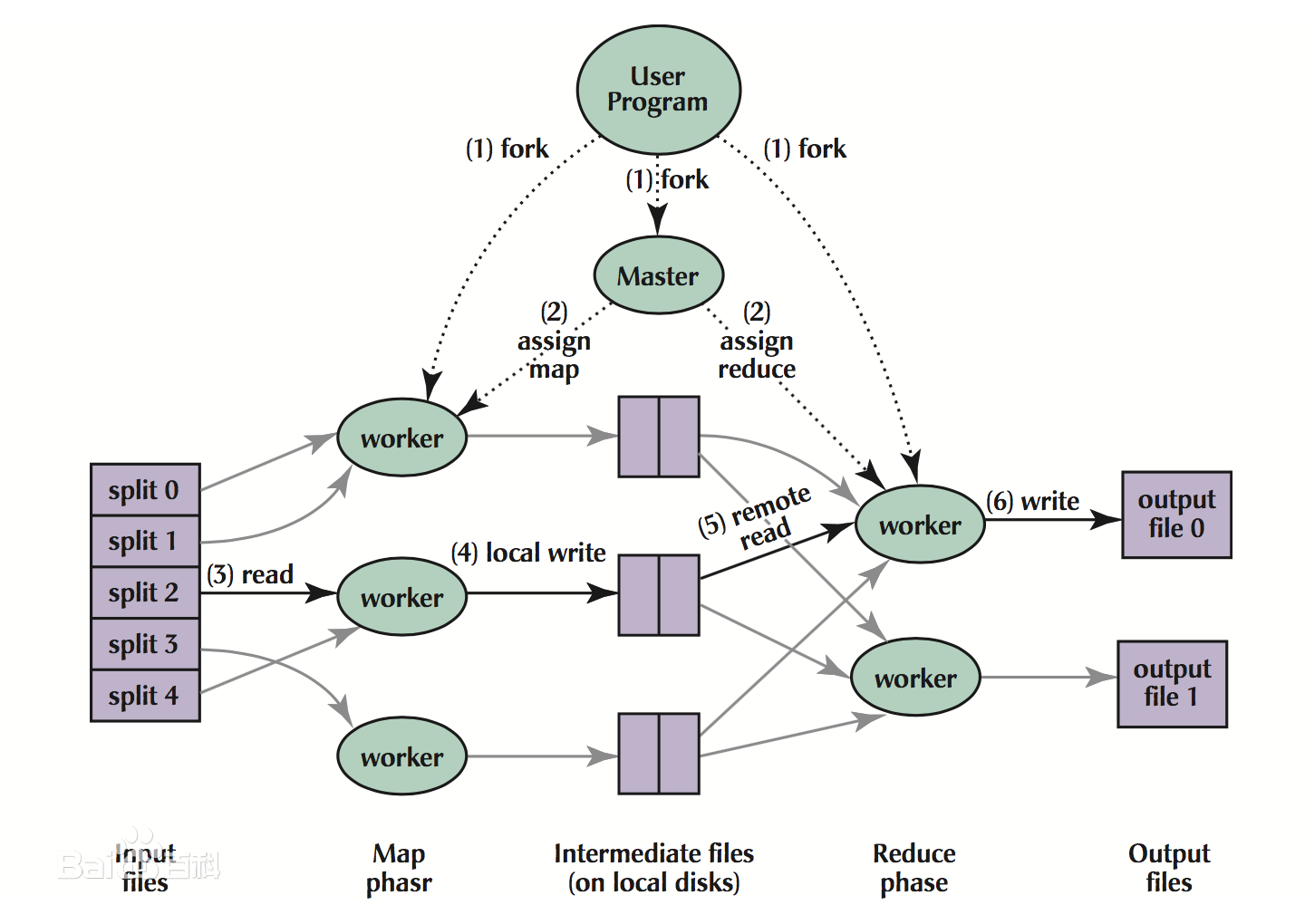
完整系统图如下:
b.正排索引 Forward Index 和倒排索引 Inverted Index
举例
正排索引就是已知文章的id可以查到文章内词语列表的索引
倒排索引就是已知词语查找文章id列表的索引
c.对于中文搜索引擎还需要使用中文分词,感兴趣可以自行了解
一个完整的搜索引擎系统如下图所示:
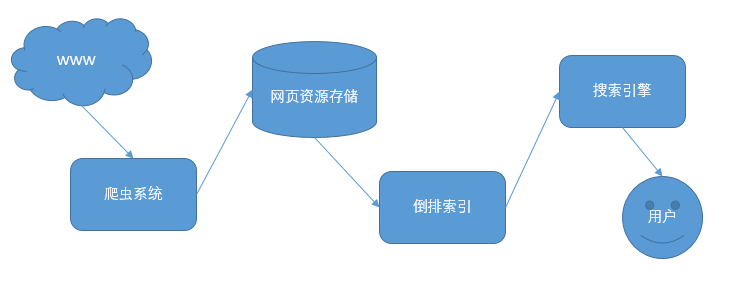
问题:首先要设计一个爬虫系统
1.明确设计需求
爬虫的目的是抓取互联网上的网页内容存储下来建立倒排索引。
一个网页中通常会有多个其他网页的链接,这些Url之间具有一定的关联性,可以看做一个图中的有向边,整个互联网就可以看成一个巨型的图。一个网页被更多其他网页指向自己,他就具有更高的价值。这就是Google提出的page rank算法。google pagerank
这时候一般会选择新闻类网站或者寻找一些排名较高的网站内容作为起始的种子网页。
假设10天内需要抓取1B的网页(每秒爬取约1000+的网页内容), QPS:1k
每个网页内容假设10kb,总共需要10Tb的存储空间。
2.设计服务
对于爬虫系统,只需要一个Crawler Service。 图上遍历通常选择BFS,因为无法预知图的深度,所以不推荐使用DFS。
爬虫系统是一个经典的生产者消费者模型,只不过爬虫既是生产者又是消费者。
使用消息队列作为缓冲区保存url,爬虫从队列中获取需要抓取的url并抓取,同时又把网页中解析出来的新url加入到队列中。
爬虫的数量不能太少也不能太多。由于网络的原因,大部分情况process处于空闲的状态,单进程的爬虫效率太低。而太多会产生过多的上下文切换,导致CPU利用率下降。所以推荐使用20台机器,每台机器启动100个进程,每个进程单独执行一个爬虫程序。
3.存储结构设计
对于数据的存储主要是3点
- 网页内容的存储
- BFS中的Queue如何存储
- BFS中的HashSet如何存储
网页内容
网页内容一般存储在分布式文件系统中,不要存储在爬虫所在的机器上。因为爬虫一般是无状态的。
无状态服务(stateless service):对单次请求的处理,不依赖其他请求,也就是说,处理一次请求所需的全部信息,要么都包含在这个请求里,要么可以从外部获取到(比如说数据库),服务器本身不存储任何信息。
而且爬取下来的网页内容还要交给索引器去创建倒排索引。
BFS中的Queue
实际工程应用中常用的消息队列,如Redis, RabbitMQ, Kafka等等
BFS中的HashSet
主要作用是避免一个网页被重复抓取,选择一个效率较高的key-value型的数据库保存即可,除了是否被爬取过,还可以存储一些其他信息。
根据上面的内容,一个简易的爬虫系统伪代码如下:
def crawler_task(url):
webpage = http_request.download(url)
distributed_file_system.save(url, webpage)
for next_url in extract_urls(webpage):
if not db.exists(next_url):
message_queue.add_task("task", next_url)
db.insert(next_url)
4.拓展系统
由于robots协议的存在,以百度为例 https://www.baidu.com/robots.txt ,robots协议中规定某些路径下面的内容禁止爬取,单纯的使用先入先出的队列会导致一个网站短时间内被多次爬取,进而导致服务器宕机或者爬虫被封。
如何限制爬虫访问某个网站的频率
让爬虫系统只做消费者,不负责新爬取任务的生成。新增一个定时任务作为生产者,负责调度和生成爬取任务,并在数据库中记录每个网站下一次可以友好抓取的时间。
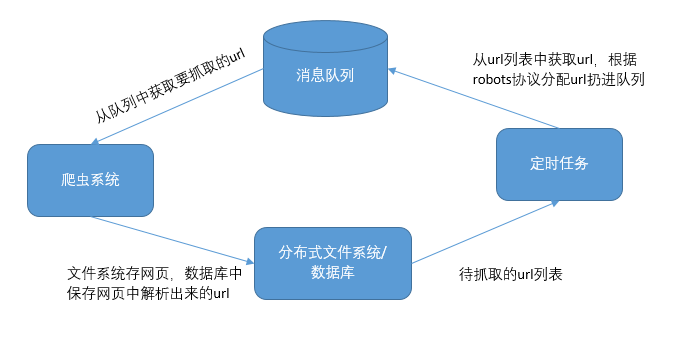
进一步的,数据库中可以按照域名区分url(url列表存在对应域名下面),数据库中也可以保存该域名下次什么时间可以被爬取等信息。定时任务遍历域名,遇到可以抓取的域名,就加入到消息队列中。
完整伪代码如下:
def crawler_task(url):
webpage = http_request.download(url)
distributed_file_system.save(url, webpage)
for next_url in extract_urls(webpage):
if not db.exists(next_url):
domain = fetch_domain(next_url)
db.append_url(domain, next_url)
def scheduler(scheduler_id):
while True:
for domain in db.filter_domain(scheduler_id):
if not good_time_to_crawl(domain):
continue;
url = db.get_url_from(domain)
message_queue.add_task("task", url)
db.update_next_available_crawl_time(domain)
如何处理网站的更新和失效
对于网页内容的更新,可以对比整个网页的MD5值,判断是否发生过变化。
但是对于系统来说,如果网页不断变化,爬虫不能也跟着不停的爬取,如果网站因为过度访问挂了,爬虫也不能够继续取访问网页内容,推荐的做法是指数退避(Exponential backoff)。
指数退避(Exponential backoff)
对于网页更新
- URL 抓取成功以后,默认 1 小时以后重新抓取
- 如果 1 小时以后抓取到的网页没有变化,则设为 2 小时以后再次抓取
- 2小时以后还是没有变化,则设为 4 小时以后重新抓取,以此类推
- 如果 1 小时以后抓取到的网页发生变化了,则设为 30 分钟以后再次抓取
- 30分钟以后又变化了,设为 15 分钟以后重新抓取。
- 设置抓取时间的上下边界,如至少 30 天要抓取一次,至多 5 分钟抓取一次
对于网页失效
- URL 抓取失效以后,默认 1 小时以后重新抓取
- 如果 1 小时以后依然抓不到,则设置为 2 小时
- 其他步骤类似网页更新的情况
