
目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
4.数据库拆分和一致性哈希
5.分布式文件系统
6.分布式数据存储系统
7.聊天系统
问题:设计一款打车软件
1.明确设计需求
列举一些核心场景
- 司机上报位置
- 乘客发起订单
- 匹配系统
搜索一些数值,2020年,网约车司机总数1.5M,假设每天同时在线人数约为600K
QPS = 600K / 4(假设司机每隔4秒上报一次位置) ~ 150K
峰值QPS = 150 * 3 ~ 450K
由于用户不会一直在线,QPS数量应该远小于司机,可以忽略不计。
需要记录当前位置信息 600K * 100bytes = 60M/天
2.设计服务
- 记录车的位置 GeoService
- 匹配打车请求 DispatchService
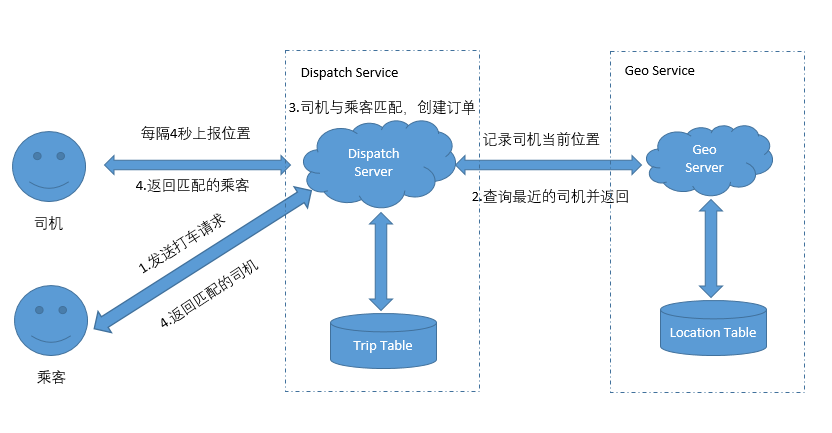
3.存储结构设计
Trip Table
| Column | Type | Comments |
|---|---|---|
| id | pk | |
| rider_id | fk | |
| driver_id | fk | |
| start_lat | float | 起点纬度 |
| start_lng | float | 起点经度 |
| end_lat | float | 终点纬度 |
| end_lng | float | 终点经度 |
| created_at | timestamp | 创建时间 |
| status | int | 订单状态 |
Location Table
| Column | Type |
|---|---|
| driver_id | fk |
| lat | float |
| lng | float |
| updated_at | timestamp |
LBS(Location Based Service)的重点在于地理位置的存储和查询
当查询某个范围内的坐标有如下SQL:
SELECT * FROM Location
WHERE lat < myLat + delta
AND lat > myLat - delta
AND lng < myLng + delta
AND lng > myLng - delta;
这个时候发现需要同时对两列进行范围查询,而复合索引不能同时对多列进行范围查询。
最好的解决办法是把二维坐标映射到一维。
-
Google S2 简单来说就是把地址空间映射到一个整数,如果两个一维整数比较接近,对应的二维坐标就比较接近,精度较高
-
相对简单一点的有 GeoHash 将二维坐标映射成一个32进制的数字,两个数值的公共前缀越长,两个点约接近
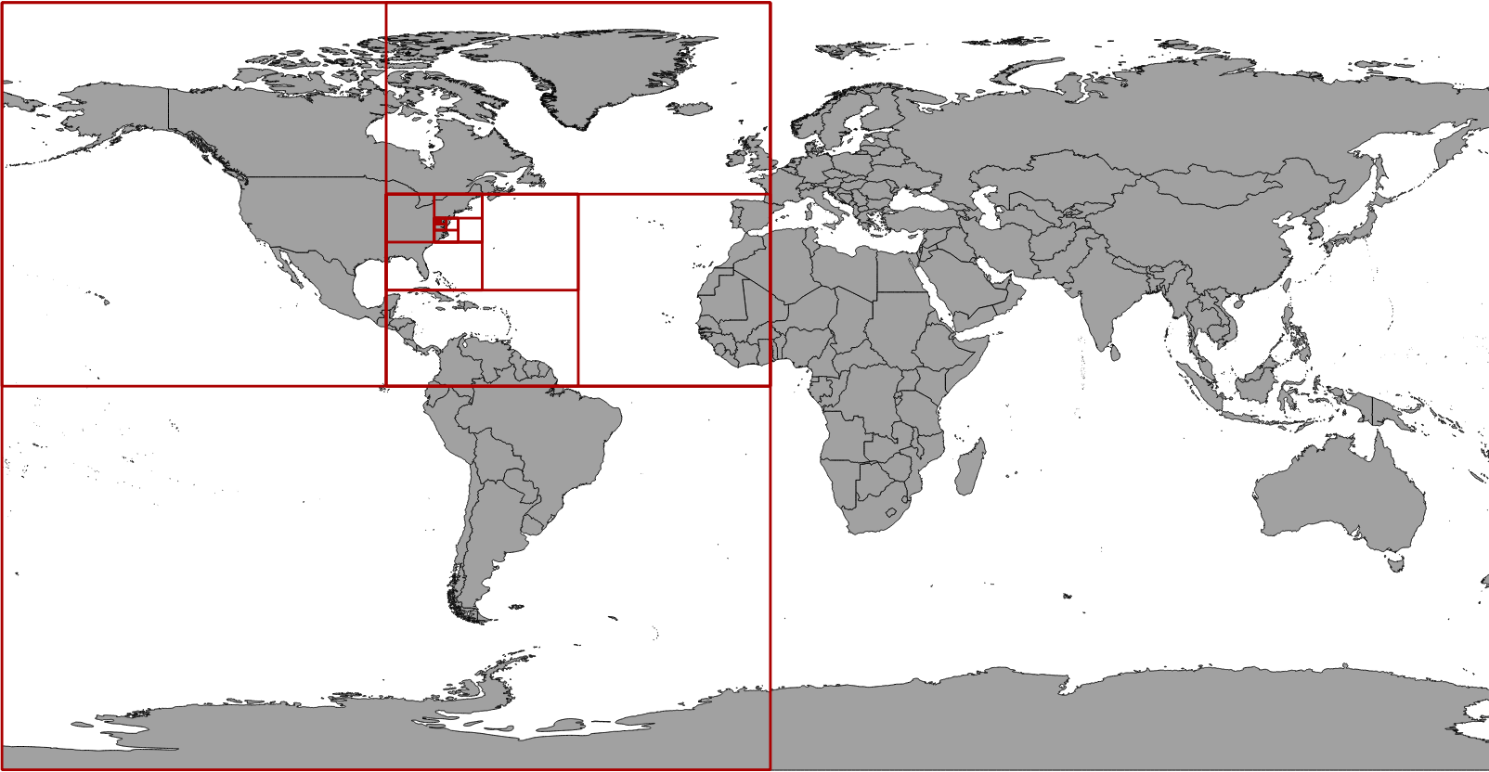
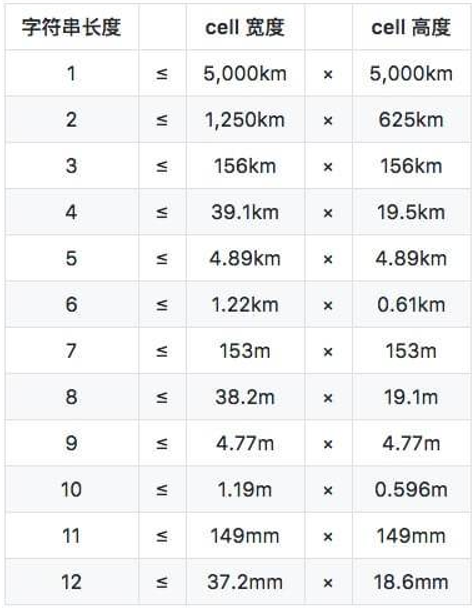
将地球展平并划分区域,对一个地理坐标不断地迭代,得到一个二进制串,再将二进制串5位一组(刚好对应32进制)翻译成字符串(例如:9q9hvu7wbq2s),分成具体编码过程可以自行了解。
一般情况下,精度在4~6位已经足够使用了
SQL数据库
首先对geohash建立索引
查询语句SELECT * FROM Location WHERE geohash LIKE "9q9hv%";
NoSQL-Redis(推荐)
按照司机的位置分级存储,使用set数据结构
还以9q9hvu7wbq2s位置,key分别保存9q9h, 9q9hv, 9q9hvt, value保存在位置范围内司机的集合
修改后的流程如下:
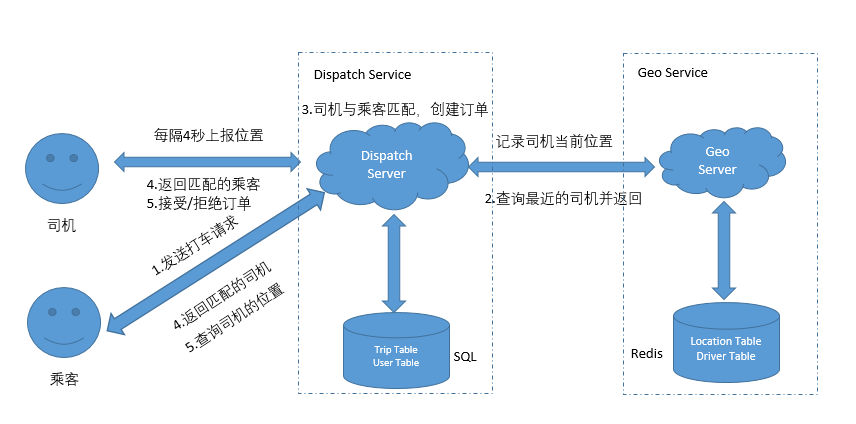
- 乘客发出打车请求,服务器创建一次trip,将trip_id返回给乘客,乘客每隔几秒询问服务器是否匹配成功
- 服务器找到匹配的司机(通过乘客的位置计算geohash,先查6位的,如果没有再查5位。。。),写入到trip,修改订单状态,同时将Driver Table中的司机设置为不可用,并存入trip_id
- 司机上报位置并在Driver Table中发现有分配给自己的订单,去Trip Table中查找对应的订单返回给司机
- 司机接受请求,修改Driver和Trip Table中的状态,乘客匹配成功,获取司机信息
- 司机拒绝请求,修改Driver和Trip Table中的状态,重新匹配司机,返回第2步
- 订单结束后,修改Driver和Trip Table中的状态,司机设置为可用
4.拓展系统
系统的主要问题在Redis,虽然Redis有更高的读写效率,但是对于商用系统,Redis保存很多重要的数据,如果宕机,损失会非常大。
分摊流量
简单做法就是做数据库拆分,可以按照geohash或者城市维度拆分,可以减少损失
