
目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
问题:访问量增大以后,如何拓展系统
单点故障(高可用性):指系统中一点失效,就会让整个系统无法运作的部件,换句话说,单点故障即会整体故障。
常用的处理方式
- 数据拆分Sharding
就是按照一定的规则把数据分开存储到不同的机器上面,这样其中一台数据库挂了,整个网站不会全挂,而且可以分摊读写流量。 - 数据复制Replica.
就是一份数据多复制几份,一台机器挂了可以用其他机器上的数据进行恢复,也可以分摊读请求。
数据拆分(数据库分片)
垂直切分
最简单的做法是把每个表分到不同的数据库中。
稍微复杂一点的做法是按照变动频率将表中的某些列拆分出去。
例如在User表中,常用的字段有Username, Email, Password, Nickname, Avatar。
相比较而言,Username, Email, Password是不会经常变动的,而Nickname, Avatar相对来说变更的几率比较高。这样就可以把他们拆分成两个表User和UserProfile,相互之间可以用外键关联,再分别放在不同的机器上,这样如果存储用户个人信息的UserProfile数据库挂了,不会影响到用户的正常登录。
垂直切分不适用于数据量过大的表,或者表中的字段很少,但是访问量比较大的时候。
水平切分
水平切分一般按照业务场景,比如按地区,时间等等。
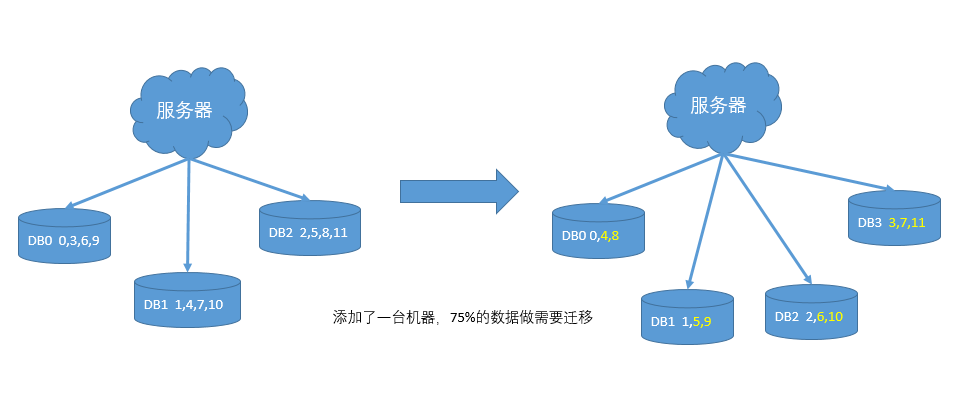
重点在于数据怎么分配,之前在短网址系统中按照机器数量取模分配。但是这样会有一个问题。当机器数量再次需要拓展的时候,大部分数据都需要进行迁移。对大量数据进行迁移的话,一个是时间较长,容易出现数据的不一致,另外迁移过程中,服务器压力比较大,更容易出现故障。
一致性哈希算法
由于一个key%n和%(n + 1)时结果差距较大,这种Hash算法就可以称为不一致Hash,为了解决这些问题,出现了一致性哈希算法。
一个简单的实现方式
模一个比较大的数字,以360为例,把这个数字分配到n台机器。分配信息记录在服务器上的一张表中,每次拓展从相邻的数据库中取走一部分数据。
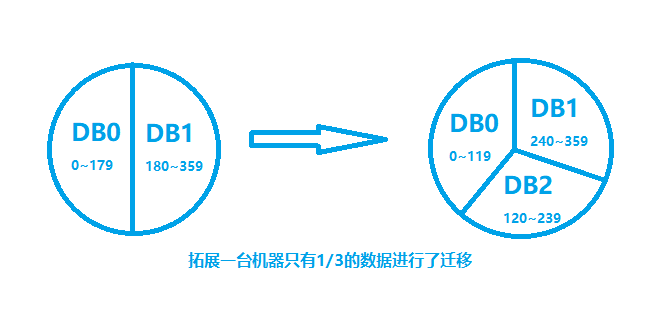
这种方式的缺点是会导致数据分布不均匀,新机器的数据从两台老机器上获取,也会造成老机器的负载过大。
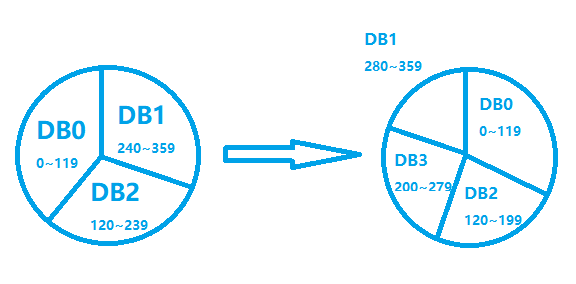
一致性哈希
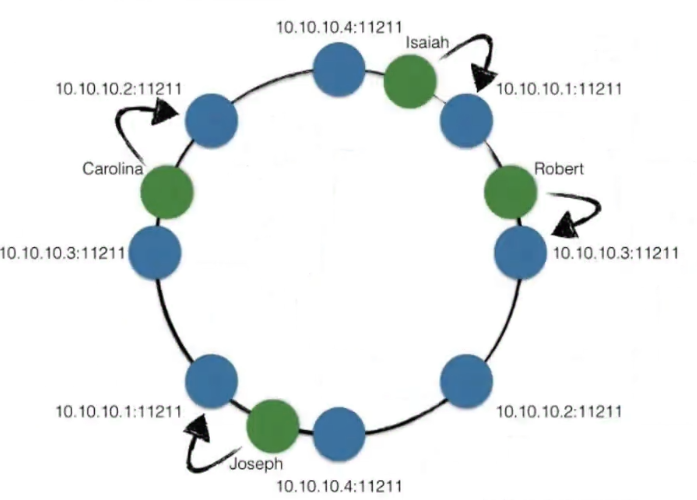
将这个模的数修改到2^32/2^64都可以,以2^64为例
把0~2^64-1看成是一个圆环,数据和机器都通过哈希函数换算成圆环上的一个点。
- 数据取主键/row_key
- 机器可以取MAC地址或者取固定名字如DB01
数据保存在哪台机器取决于在圆环上顺时针碰到的下一个机器节点。
当新增机器D的时候,将数据从机器A迁移到机器D,数据的移动只发生在A和D之间
当删除机器B的时候,将数据B中的数据迁移到数据C上即可,其他数据不会受到影响
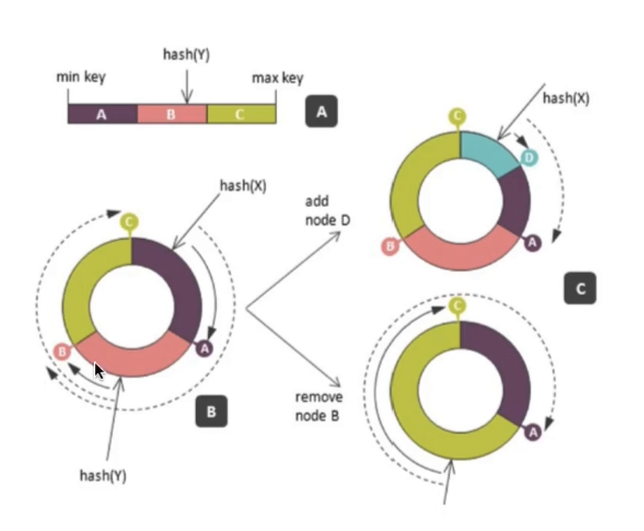
仅仅是这样的话还是存在问题。如果机器数量比较少,那么通过哈希函数计算的值可能会分布不均匀,极端情况下可能大部分数据都会分配到一台机器上。或者一台数据库崩溃,大量的数据迁移到顺时针的数据库上,大量数据堆积,造成连续的崩溃,从而导致整个系统的崩溃。
虚拟节点
为了解决这个问题,方法就是想办法让节点数量尽可能的多,让各个节点尽可能的分布均匀,由此引入虚拟节点的概念。
将一个实体机器生成若干个分身(虚拟节点),分身的key可以用机器的key+后缀,如DB01_0001。
数据复制
backup
- backup一般是周期性的,比如一个晚上备份一次
- 数据丢失以后只能恢复到某个时间点
- 不能用作在线的数据服务,不能分摊读的QPS
replica
- 一般是实时的,数据写入的时候就会产生多份副本保存起来
- 数据丢失可以直接通过其他副本恢复
- 可以用于在线的数据服务,分摊读的QPS
以MySQL为例,通常采用主从模式,Master负责写,Slave负责读,Slave可以从Master中同步数据。
预写日志(Write-Ahead log)
1. 数据库的任何操作,都以Log的形式做一份记录,比如A从B时刻从C改成了D
2. Master有操作通知Slave读取log,因此Slave上面的数据有一定的延迟
3. 如果Master挂了,Slave可以通过选举升级为Master,承担读和写的工作,但是可能会造成一定程度的数据丢失或者不一致。
数据拆分举例
一个原则:怎么取数据就怎么拆数据
User表
大部分情况是按照UserId查找,一般只有在登录的情况下可能会用到Username进行查询。
面临的问题就是多台数据库没法维护全局的自增Id。
可以使用UUID作为UserId,根据哈希函数到对应的数据库查询。
如果一定要使用自增id,可以单独用一个服务来负责创建id,每次有新用户创建时,查询当前UserId的最大值,每次+1即可,但是要进行加锁来保证数据操作的原子性。
因为创建用户的QPS不大,才可以这么做,加锁的影响不会很大
提交记录
一条提交记录主要包含user(用户), timestamp(提交时间), problem(题目), status(判定结果)
- 查找某个题目的全部提交记录
- 查看某个人的所有提交记录
单纯按照UserId或者ProblemId拆分都无法同时满足 两个查询需求
解决方案
创建两个表,提交记录表按照UserId拆分,因为UserId的查询操作相对会多一些。
除此之外再创建一个表,记录某个题目有哪些提交记录,用ProblemId作为拆分的Key。
