目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
4.数据库拆分和一致性哈希
问题:分布式文件系统(Distributed File System)怎么有效的存储数据?
1.服务器通信
重点在于多台服务器之间如何沟通?
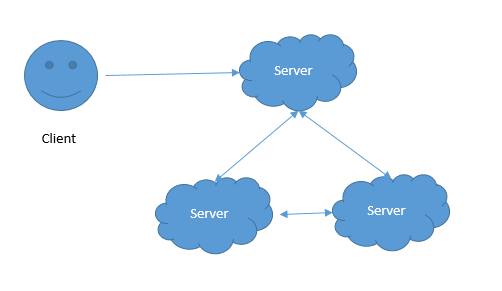
Peer to Peer
每台服务器独立工作,可以访问任意一台服务器。这种方式的好处是一台机器挂了,其他机器仍然可以工作,缺点是需要经常通讯保持数据一致。
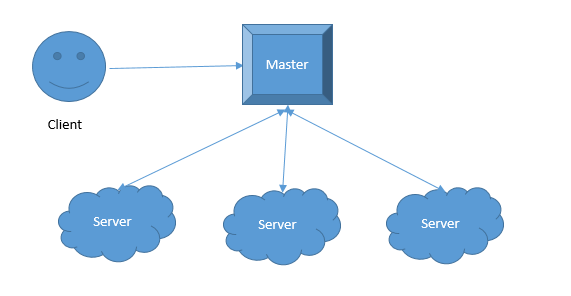
Master Slave
比较推荐的实现是主从模式,由Master节点负责管理客户端对文件的访问。这种设计相对比较简单,数据也容易保持一致,但是会有一些延迟,而且Master宕机,也要面临数据一致性和服务可用性的抉择。
2.文件的存储结构
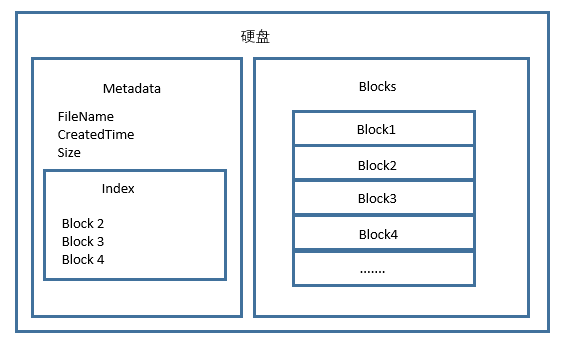
单台机器存储100G文件
一个文件会包含一些存储信息,如名称,大小,创建日期,这些被称为Metadata。文件内容一般要和Metadata分开保存,因为用户在获取文件列表的时候会读取到所有文件的Metadata,而不需要读取文件的所有内容。文件内容本身也要分开存储,拆分成若干个文件块(Block)。如果连续存储,修改文件内容的时候需要整体挪动后面的文件块。一般一个文件块存储4096byte内容。
单台机器存储100T文件
当文件大小达到100T的时候,这么大的文件需要拆分成25*1000*1000*1000个block。这时候需要优化一下,可以将文件拆分成一些大块(Chunks),一般一个Chunk大小为64M。这样的好处是可以减少Metadata中需要存储的内容,缺点是对于较小的文件,也会占用64M的空间,会浪费一些空间。
存储10Pb文件
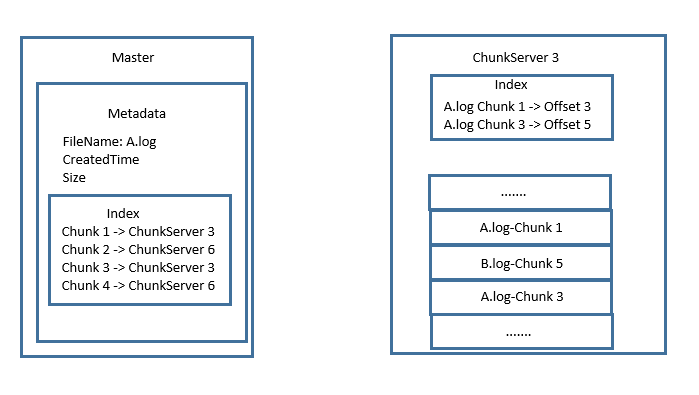
使用主从模式,Slave节点作为ChunkServer,Master节点上存储文件的Metadata,记录每个Chunk保存在哪台ChunkServer上面。ChunkServer除了存储文件内容,也可以记录文件的Chunk存储在自己硬盘上的偏移量,方便查询。
3.明确设计需求
- 读取文件
- 写入文件
主要需要计算下Metadata存储空间,通常1 Chunk的Metadata需要64B的存储空间,10Pb文件的Metadata容量大约需要10G。
4.设计服务
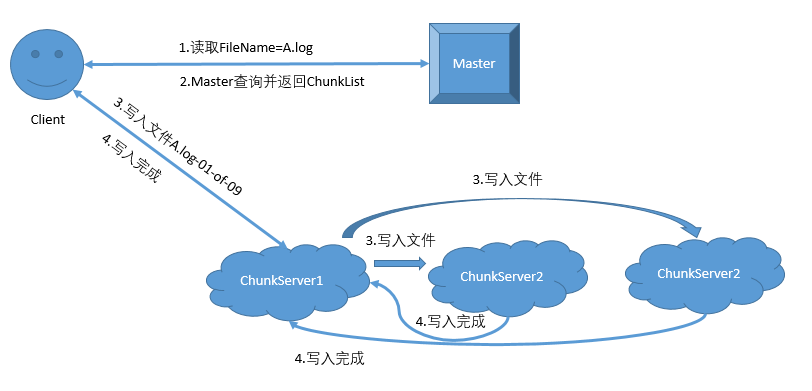
写入服务
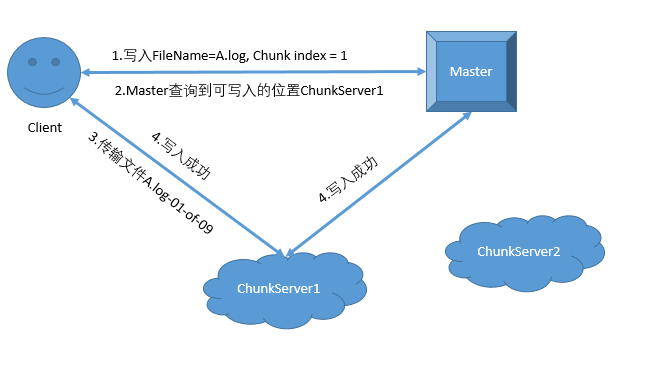
写入过程一般也将文件按照Chunk大小多次传输,如果传输失败只需要重新传一小部分。
写入流程如下:
如果要修改某个文件怎么处理?
因为文件系统也是一个读多写少的系统,修改文件时可以牺牲部分性能,使用最简单的方式,先将整个文件删除后重新写入一份。
读取服务
同理读取文件时也是拆分成多次读取,Master提供文件所包含的Chunk列表,最后由clinet端合并文件内容并返回结果。
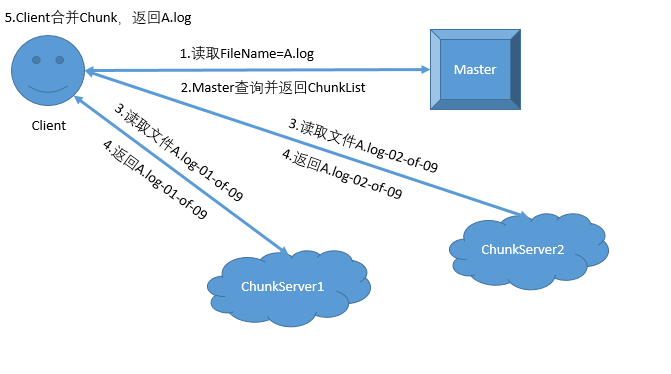
Master节点的主要任务就是存储各个文件的Metadata, 以及文件和ChunkServer之间的对应关系,在读取的时候找到对应的ChunkServer,写入的时候分配空闲的ChunkServer.
5.系统拓展
怎么知道Chunk是否已经损坏?
CheckSum
校验和
核心在于对进行很小的修改的输入数据都会输出一个显著不同的值,如果在github下载开源软件的时候,一般都会提供一个MD5值,以便判断文件是否被恶意修改。
以MD5为例,一个Chunk创建一个CheckSum,需要占用4byte空间,1Pb的文件则需要1P / 64Mb * 4 = 62.5Mb.
当写入一个Chunk的时候就可以计算CheckSum,当读取数据的时候重新计算一下CheckSum,并且和现在的值进行比较就可以知道文件内容是否发生过变化。
ChunkServer挂了怎么办?
最简单的方法是做备份Replica。假设有3台ChunkServer,推荐的放置方式是2台服务器放在一起,另外一台放在不同的地方,这样放在一起的服务器可以保证服务器之间的快速访问。分开放置可以保证比如某地机房发生故障的时候,系统仍然可以正常运行。
发现Chunk损坏怎么通过Master的帮助进行恢复?
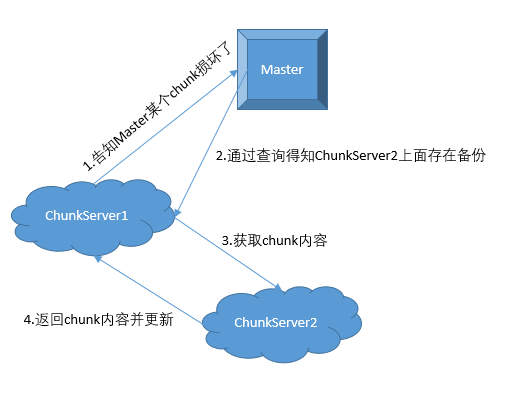
写入服务的优化
当ChunkServer进行备份以后,发现Client端变成了系统的瓶颈,每次写入文件都需要对每个ChunkServer发出请求。
优化的方法是通过队长模式,服务器内部之间传输文件效率是比客户端与服务器之间高。通过选取队长的方式(距离最近、现在空闲的服务器),这样客户端只需要与ChunkServer进行一次传输,剩下的任务由队长分配完成。