
题目描述
想象一下你是个城市基建规划者,地图上有 N 座城市,它们按以 1 到 N 的次序编号。
给你一些可连接的选项 conections,其中每个选项 conections[i] = [city1, city2, cost] 表示将城市 city1 和城市 city2 连接所要的成本。(连接是双向的,也就是说城市 city1 和城市 city2 相连也同样意味着城市 city2 和城市 city1 相连)。
返回使得每对城市间都存在将它们连接在一起的连通路径(可能长度为 1 的)最小成本。该最小成本应该是所用全部连接代价的综合。如果根据已知条件无法完成该项任务,则请你返回 -1。
提示:
1 <= N <= 10000
1 <= conections.length <= 10000
1 <= conections[i][0], conections[i][1] <= N
0 <= conections[i][2] <= 10^5
conections[i][0] != conections[i][1]
样例
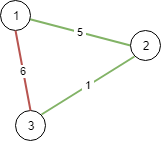
输入:N = 3, conections = [[1,2,5],[1,3,6],[2,3,1]]
输出:6
解释:
选出任意 2 条边都可以连接所有城市,我们从中选取成本最小的 2 条。
算法分析
小堆优化 prime算法思想
将节点分为两类,
1:已访问节点集合(已成功为最小生成树部分,必定相连的)
2:未访问节点集合
讨论两个集合如何相连的花费最小,只需要利用贪心思想,选取
已访问集合 和 未访问集合 之间 相连 的所有边中权重最小的便是最小花费
当已访问集合与未访问结合相连的边为0
如果已访问数量与总节点数相等,存在最小生成树,如果不等,说明
未访问集合还有节点,造成独立,不能相连成生成树
时间复杂度O(nlgn)
故这种思路很容易想到利用并查集,便是所谓的kruskal算法
prime算法是基于点的考虑,而kruskal是基于边的考虑
并查集 kruskal算法思想
把所有边入小堆,每次便取剩下小的边,
边分为两种情况:
一:两头在同一集合,跳过
二:两头不在同一集合,入图,并查集维护
若全图连通,存在最小生成树,若不连通,不存在
除了用堆还可以直接排序,复杂度均相同
时间复杂度 O(nlgn)
prime 基础版
class Solution {
public:
inline int minimumCost(int n, vector<vector<int>>& connections) {
int int_max = 0x3f3f3f3f;
vector<int> dist(n+1,int_max);
vector<bool> vis(n+1,false);
vector<vector<pair<int,int>>> g(n+1);
for(auto& c : connections){
g[c[0]].push_back({c[1],c[2]});
g[c[1]].push_back({c[0],c[2]});
}
dist[1] = 0;
int cv = -1,now = 1,ans = 0;
while(++cv < n){
int mi = int_max;
for(int i = 1; i <= n; i ++){
if(!vis[i] && mi > dist[i]){
mi = dist[i]; now = i;
}
}
vis[now] = true;
ans += mi;
for(auto &[v,w] : g[now]){
if(dist[v] > w && !vis[v])
dist[v] = w;
}
}
return ans > int_max ? -1 : ans;
}
};
prime+堆优化
C++ 代码
#define pii pair<int,int>
class Solution {
public:
int minimumCost(int n, vector<vector<int>>& connections) {
//1:领接表图g,标记vis,小堆q 初始化
vector<vector<pii>> g(n + 1);
vector<bool> vis(n + 1);
priority_queue<pii, vector<pii>, greater<pii>> q;
//2:建无向图
for (auto x : connections) {
g[x[0]].push_back({x[1],x[2]});
g[x[1]].push_back({x[0],x[2]});
}
// 3:选点1,距离0,队列元素[d,u]
q.push({0,1});
int ans = 0, k = 0;
// 4:利用小堆对d取最小,已访问跳过,未访问计入,标记,
// 将相邻边且对应节点未访问入堆
while(!q.empty()) {
auto [du,u] = q.top(); q.pop();
if (vis[u]) continue;
ans += du; k ++;
vis[u] = true;
for (auto [v,dv] : g[u])
if (!vis[v])
q.push({dv,v});
}
return k == n ? ans : -1;
}
};
kruskal + 并查集
C++ 代码
class Ufs{
vector<int> p;
public:
Ufs(int n){
p.resize(n+1);
for(int i = 0; i <= n; ++i)
p[i] = i;
}
int find(int x){
return x == p[x] ? x : find(p[x]);
}
void uni(int x,int y){
p[find(x)] = find(y);
}
};
class Solution {
public:
int minimumCost(int n, vector<vector<int>>& conn) {
Ufs u(n);
sort(conn.begin(),conn.end(),[&](auto &a,auto &b){
return a[2] < b[2];
});
int e = 0, ans = 0;
for(auto c : conn){
int x = c[0], y = c[1], d = c[2];
if(u.find(x) != u.find(y)){
u.uni(x,y); e ++;
ans += d;
}
if(e == n - 1) break;
}
return e == n-1 ? ans : -1;
}
};
kruskal算法优化主要在并查集上,可以使用路径压缩
并查集其实便是一棵树,尽可能平衡这棵树,优化往上查找时间,引入秩,等同于树高
以下并查集优化按秩合并
优化版本
class Ufs{
vector<int> p;
vector<int> rank;
public:
Ufs(int n){
p.resize(n+1);
rank.resize(n+1);
for(int i = 0; i <= n; ++i){
p[i] = i; rank[i] = 1;
}
}
int find(int x){
return x == p[x] ? x : find(p[x]);
}
void uni(int x,int y){
int rx = find(x), ry = find(y);
if(rx != ry){
if(rank[rx] > rank[ry]){
p[ry] = rx; rank[rx] += rank[ry];
}else{
p[rx] = ry; rank[ry] += rank[rx];
}
}
}
};
class Solution {
public:
int minimumCost(int n, vector<vector<int>>& conn) {
if(n - 1 > conn.size()) return -1;
Ufs u(n);
sort(conn.begin(),conn.end(),[&](auto &a,auto &b){
return a[2] < b[2];
});
int e = 0, ans = 0;
for(auto c : conn){
int x = c[0], y = c[1], d = c[2];
if(u.find(x) != u.find(y)){
u.uni(x,y); e ++;
ans += d;
}
if(e == n - 1) break;
}
return e == n-1 ? ans : -1;
}
};
