
KMP字符串
题目描述
给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P 在字符串 S 中多次作为子串出现。求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1≤N≤10^5,1≤M≤10^6
输入样例:
3
aba
5
ababa
输出样例:
0 2
思路分析
暴力写法
所谓暴力,就是直接去模拟出来这个一般过程就好了,没有一点儿拐弯抹角的地方,ok,接下来分析一下该怎么模拟这个过程。
现在我们有两个已知长度的字符串,一个是 S,另一个就是 P,其中 P 是模式串,然后 P 多次作为子串在 S 中出现,我们要
做的就是找到并输出所有 模式串 P 在 S 中所有出现的位置的起始下标
我们可以设置一个二层循环,第一层循环枚举 S 的下标,第二个循环枚举的是 P 的下标,然后逐个对比就好了,如果二者对应的位置相等的话
就继续比较,即二者的下标都增加,如果不相等,就直接跳出循环,ok 展示一下暴力写法的核心代码
// 这连个字符串都是从下标是 1 的位置开始存的,所以从 1 开始枚举
// m 是 S 的长度, n 是 P 的长度
for (int i = 1; i <= m; i ++){
int t = i;
// 定义了一个 t 作为跟随,不直接改变 i 的值
bool flag = true;
/* 先假设 i 是起始坐标,然后逐个进行对比,如果相等,二者坐标都往后挪,
再进行判断,如果二者不相等,就改变 flag 的值,然后退出
*/
for (int j = 1; j <= n; j ++, t ++){
if (p[j] != s[t]){
flag = false;
break;
}
}
if (flag) printf("%d ", i - 1);
// 如果说假设成立,就输出
}
然后进行整体带入哈,下面是暴力写法整体代码展示
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010;
int n, m;
char s[M], p[N];
int main(){
cin >> n >> p + 1 >> m >> s + 1;
for (int i = 1; i <= m; i ++){
int t = i;
bool flag = true;
for (int j = 1; j <= n; j ++, t ++){
if (p[j] != s[t]){
flag = false;
break;
}
}
if (flag) printf("%d ", i - 1);
}
return 0;
}
暴力写法时间复杂度分析
上面这个暴力代码提交,会超时的哈, n 的数据范围是 十万,然后 m 的数据范围是 一百万
因为设置了一个二层循环吗,所以最坏时间复杂度就是二者的乘积,就是 10 的 11 次方,大于 10 的 8 次方
所以会超时,然后可以考虑一下怎么进行优化了
优化写法
前缀 & 后缀
在开始说优化写法之前,先来说一下两个概念,一个是前缀,一个是后缀,我们用具体的一个 串 来给大家说一下,
什么是前缀,什么是后缀,比方说 “abcd”,谁是这个串的前缀呢 ,”a”,”ab”,”abc” 都是前缀,那,谁又是这个串的
后缀呢, “d”,”cd”,”bcd” 都是后缀,所谓前缀,就是除了最后一个字符,所有以 第一个字符作为开头,以中间
任意一个字符作为结尾的子段的集合,那么,所谓后缀,就是除了第一个字符,所有以 最后一个字符作为结尾,以中间
任意一个字符作为开头的字段的集合,那么,我们还可以得知,如果有一个字符串,其中只包含了一个有效字符,如 “a”,
那它是没有前后缀的说法的哈,也就是说,我们要讨论前缀和后缀的话,起码得包含两个字符
优化的核心是什么
现在我们想一下我们该怎样进行优化,导致时间复杂度呈现 O(n * m) 的原因,是不是就是因为我们是逐个枚举的,对吧,
我们是否有必要逐个枚举,这是不是我们优化,所要考虑的问题,是,对吧,我们的核心,是要找出 P 中 有所 “重复” 的部分
什么样的优化方案
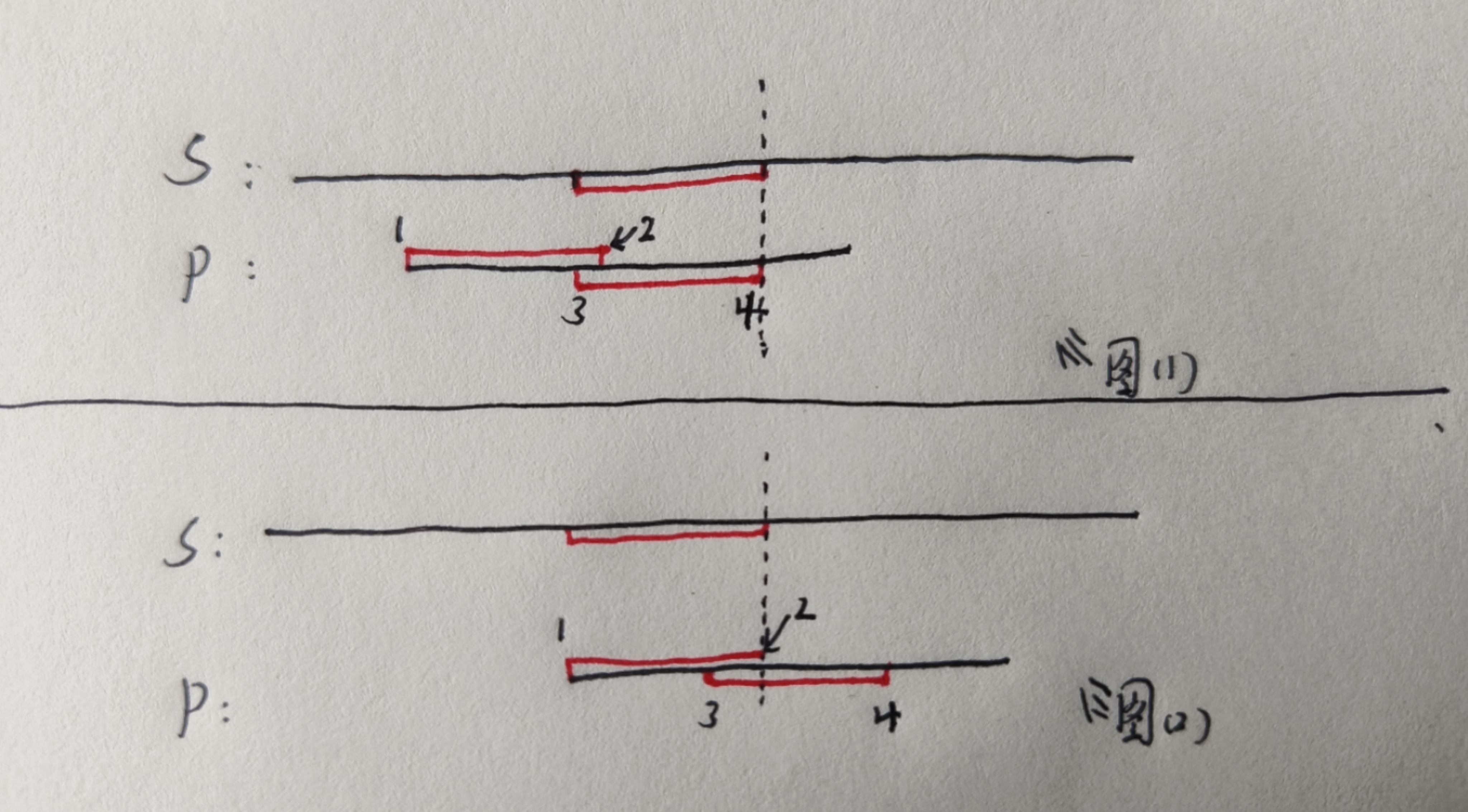
假设两个串进行对比,对比到了 图(1) 所示的位置,对比到竖向虚线处,发现再往后对比,欸,不相等了,怎么办,
我们是不是就该(相对于S)往右挪 P 了,但是我们如果还是逐个挪的话,是不是还是暴力做法啊,对的,所以,我们
不再逐个往后挪了,我们采用一挪挪一大截的挪法,关键就是这一大截,是什么
我们前面讲了两个概念哈,一个是 前缀,一个是 后缀,我们说的这个 “一大截”,就是指的前缀和后缀,但是需要注意是,
我们应该找什么样的前缀,什么样的后缀,总不能找两个不相同的后缀吧,那样子一挪,就不对了对吧, 所以,我们要找的
这个前缀和后缀,要保证二者相同
好,我们看上图哈,现在就是对比到竖向虚线处了,再往后对比,不相同了,因为要做优化,我们得往后挪,还不能只是
单纯的逐个往后挪动,我们要尽可能地一段一段地往后挪,在 上图 图(1) 中,在 P 串,假设以 1 为开头,以 2 为结尾的前缀,和
以 3 为开头,以 4 为结尾的后缀相同,并且 从 4 开始往后的位置(竖向虚线处),S 和 P 对应的序列就不相同的话,我们是不是
就可以(相对于 S)把 P 往后挪,知道原来 1 的位置,到了 原来 3 的位置就行了对吧,因为二者是相同的,所以原来 2 的位置,现在
就到了原来 4 的位置了,如上图 图(2)
方案的可行性
这样做的可行性是啥,这样做的可行性,在于 上图 图(1) 中,竖向虚线之前的 P 序列,是和其上方对应的 S 序列是相同的,
那么 P 中 3 ~ 4 序列肯定也是对应相同的,而且 P 中 1 ~ 2 序列 和 3 ~ 4 序列也是相同的,所以,这个优化方案是可行的
相等前后缀组合的确定
在一个串中,或者这个串的部分序列,比方说 “abababab” 这个串,其中,相等的前缀和后缀的组合,分别有 (“ab” 和 “ab”)
(“abab” 和 “abab”) (“ababab” 和 “ababab”) 对吧,这是不是就牵扯出来一个性质,“相等前后缀组合的不唯一性” (不知道
有没有这个性质啊,反正就是这么个说法,理解就行)那么,我们该选择哪一个相等的前后缀组合,进行“一大截一大截地挪动”呢
我们是选择短的还是选择较长的,还是选择不长不短的呢,答案肯定是确定的哈,我们应该选择较长的,为什么呢,欸,看图
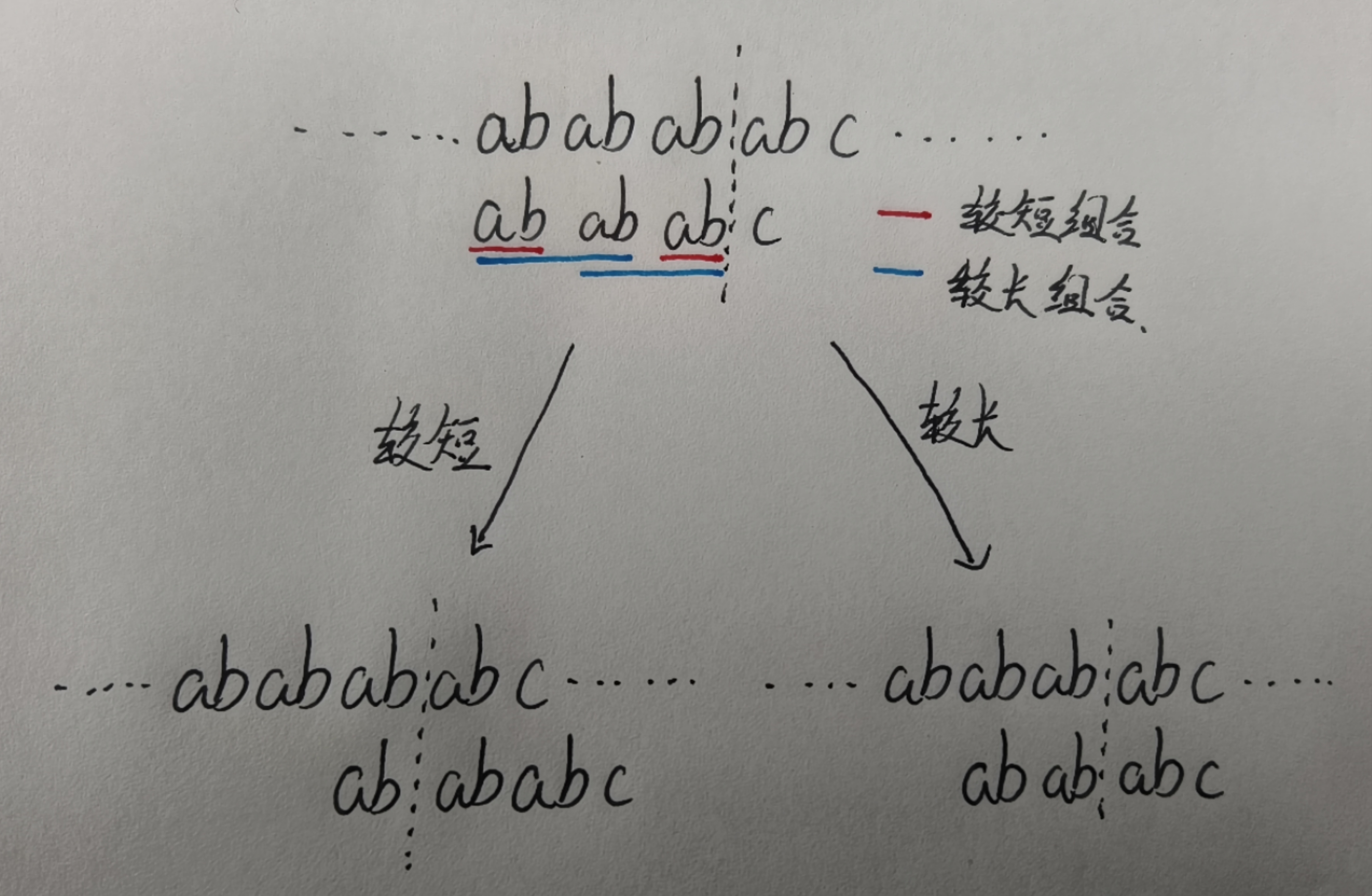
我们还是假设对比到了某个位置,然后再往下对比,发现不相同了,然后就该往后挪了,对吧,现在上面的是 S ,下面的是 P
然后用了两种颜色的笔对相同的前后缀组合做了标记,然后红色标记是较短的组合,蓝色标记是较长的组合,现在我们分别对其进行挪动
等一下,不是较长组合,更具体点来说应该是最长相等前后缀组合,然后挪动完成之后,就是两种箭头指向的情况,当然哈,这是精心设计的
比较一般的序列,我们通过箭头指向的两种情况,我们可以很明显的发现,如果挪动较短的相同的前后缀的组合,我们可能会
漏掉某些答案,因为挪动完成之后,我们肯定会从竖向虚线继续往后对比的对吧,如果用那个较短的组合进行挪动,我们可以发现,向后对比
不了几个位置,就又不相同了,就会再进行挪动,但是呢,就漏掉了一种(或多种可能的)结果,但是选择较长的相等的前后缀组合
我们就可以避免这种情况的发生对吧
结论:
选择最长的相等的前后缀组合进行挪动操作,其实就是相当于,在不漏掉某种或者多种可能的结果的情况下,尽可能较多的相对于 S 往右挪动 P
代码怎么写 ?
前面费尽口舌的分析了一大堆,分析的再透彻,我们最后还是得落实到代码上去,不然说再多都是白搭的
第一步做什么
我们核心的优化是什么,就是尽可能多个而不是逐个往后挪动 P 的位置了对吧,这个挪的过程怎么实现
我们主要通过定义一个整型数组 ne[N],这其中 ne[i] 代表着什么呢,我们举个例子还是
idx 0 1 2 3 4 5 6 7 8
P a b a b a b c c
ne[i] 0 0 0 1 2 3 4 0 0
现在我们拿 “abababcc” 来举例哈,假如说,我们现在对比一部分了,比如”ababab”这段对比好了,再往后对比,欸,不相同了,
接下来就是该往后挪了,对吧,其实说往前跳好像更形象哈,”ababab” 中最后一个 b 对应的 idx 是 6 对吧,ne[6] 是 4,是不是
就是 “ababab” 这个串的最长相等前后缀组合中前缀的最后一个元素的下标 idx 啊,顺便再说一点,假设我们现在已经往后挪了,
然后再开始从那个 “竖向虚线” 再开始往后对比对吧,如果说后面还不相等怎么办,那就继续往后挪,我们刚刚挪完之后,就是相当于
是 “abab” 之后就不相等了对吧,我们还要再往后挪,那么就是该挪到 “abab” 这个串的最长相等前后缀组合中前缀的最后一个元素的
下标 idx 了对吧,同理,如果还是不相等,那就继续往后挪,直到从头开始比较
如果说对比到最后了,也就意味着,S 中这段序列和 P 是相等的对吧,我们首先要输出这个 起始位置的坐标,然后还要继续往后对比
对吧,我们还让 P 继续挪就好了,就是挪到 ne[n](设 n 为P的长度) 的位置,再接着上面的步骤继续就好了
这个 ne[i] 存储的就是,从前面开始 到 以下标以 i 作为结尾的串的最长前后缀组合中前缀的最后一个元素的下标
我们第一步要做的就是预处理字符串 P 即 初始化 ne[N]
初始化 P ,其实也像是对比 P 和 S 一样,但是不同是就是 对于 P 的预处理,我们是从 下标为 2 的位置开始进行的,因为前面说了
讨论前后缀,字符串长度起码得是两个起步,从 下标为 2 的位置开始,也可以保证初始化出来的 ne[N] 中,数值的大小严格小于 P 的
长度,对于 P 的处理,我们主要也是设置两个指针,一个是从 2 开始,另一个是从 0 开始,先展示一下核心代码
for (int i = 2, j = 0; i <= n; i ++){
while (j && p[i] != p[j + 1]) j = ne[j];
/*
如果说对于P已经对比到 j 了,但是再往后对比不行同了,那就指向 P 的元素的指针
就往前跳,知道跳到了再往后对比,相同的位置,并且不是 坐标为 0 的位置
*/
if (p[i] == p[j + 1]) j ++;
// 如果说下标 j 后紧挨着的元素相同, 就继续往后对比
ne[i] = j;
// 记录的就是往前符合上述分析要求的最优的前缀的最后元素的坐标
}
再接下来就是对比 P 和 S 了
上代码
// 这里 i 和 j 两个指针分别指向 S 和 P
for (int i = 1, j = 0; i <= m; i ++){
while (j && s[i] != p[j + 1]) j = ne[j];
// 如果不行同, 就往前跳,最多跳到 P 的开端的前一个元素的坐标 即 0
if (s[i] == p[j + 1]) j ++;
// 如果说下标 j 后紧挨着的元素相同, 就继续往后对比
if (j == n){
// 判断 j 的长度是不是等于 n 了,如果等于 就输出 P 的起始坐标
printf("%d ", i - n);
// 因为下标是从 0 开始的,此处写成 printf("%d ", i - n + 1 - 1) 更容易理解
j = ne[j];
// 然后再往前跳,又是一个新的开始
}
}
整体代码展示
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010;
int n, m, ne[N];
char s[M], p[N];
int main(){
cin >> n >> p + 1 >> m >> s + 1;
for (int i = 2, j = 0; i <= n; i ++){
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i ++){
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++;
if (j == n){
printf("%d ", i - n);
j = ne[j];
}
}
return 0;
}
时间复杂度分析
一共有连个核心的循环部分哈,我们看下面这层循环的分析
第一层,那个基数肯定是 m 了,无疑啊这是,下面就是里面这一层了,它的基数是多少?
现在我能想到的我觉着最恶心的例子就是,连个串的长度都拉到了最大
其中它们两个只有最后一个元素不同,其他的都相同,那么这么想的话就是,当对比到
P 的最后一个元素时,后面的不相同,按照我们写的代码,每次最多就是只往前跳动一个单位
然后再往后对比,发现不同,再跳,再对比,就是陷入 j ++ 和 j = ne[j] 的循环往复中,
直到对比完成,所以最坏时间时间复杂度就是 O(2 * m) 了,也就是 O(n) 级别了,可以过的哈

厉害
还请多多关照,若有错误的地方,还望指正