
Trie树
介绍
字典树实际上就是通过利用不同字符串前缀相同的特点,来对字符串进行高效存储和查找的一种数据结构。使用一个二维数据来进行存储,第一维用来区分不同的前缀,第二维表示方向(26个字母总共26个方向)。
字典树主要支持两种操作,一种是插入,一种是查询,无论是插入还是查询基本思路都是对该字符串的每个字母进行枚举,判断当前缀为p时,当前这个结点是否存在,如果不存在则进行分配,并将前缀移动到当前结点。
解析
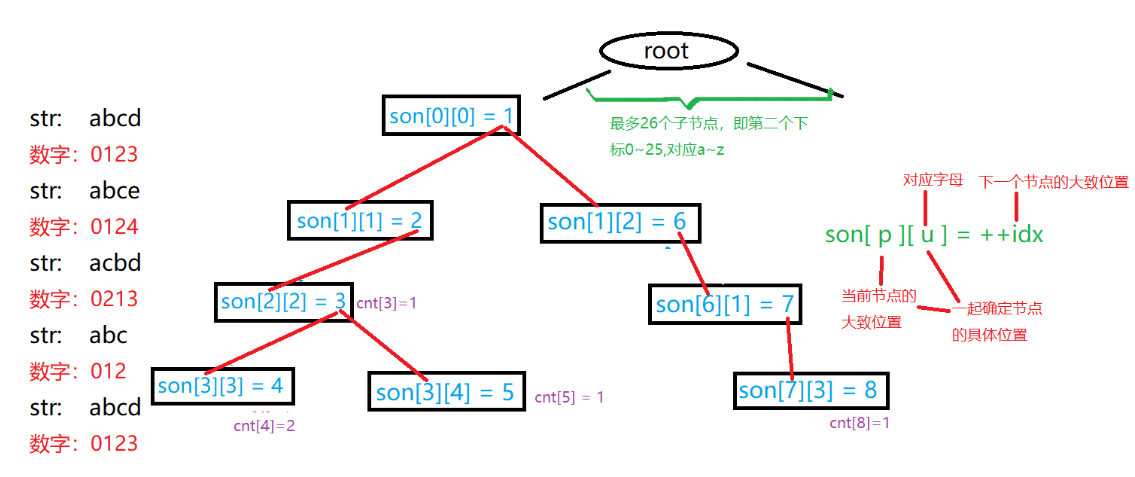
Trie树中有个二维数组 son[N][26],表示当前结点的儿子;如果没有的话,可以等于++idx。Trie树本质上是一颗多叉树,对于字母而言最多有26个子结点。所以这个数组包含了两条信息。比如:son[1][0]=2表示1结点的一个值为a的子结点为结点2;如果son[1][0] = 0,则意味着没有值为a子结点。这里的son[N][26]相当于链表中的ne[N]。
int son[N][26], cnt[N], idx;就是一个就是一个邻接表,son[N][26]就是分配的N个节点给trie使用,同时每个节点有26个状态,每次只有一个状态是成立的,而表头就是son[0][26]每个状态对应一个开头。
而insert操作就是一个尾插法,有头节点的链表尾插就要遍历到最后一个元素。这个for循环就是在做这个操作
void insert(char str[])
{
int p = 0; //从根结点开始遍历
for (int i = 0; str[i]; i ++ )
{
int u =str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx; //没有该子结点就创建一个
p = son[p][u]; //走到p的子结点
}
cnt[p] ++;
}
而每次查询
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
就是一次邻接表的遍历过程,如果路径不通就返回0。
图解
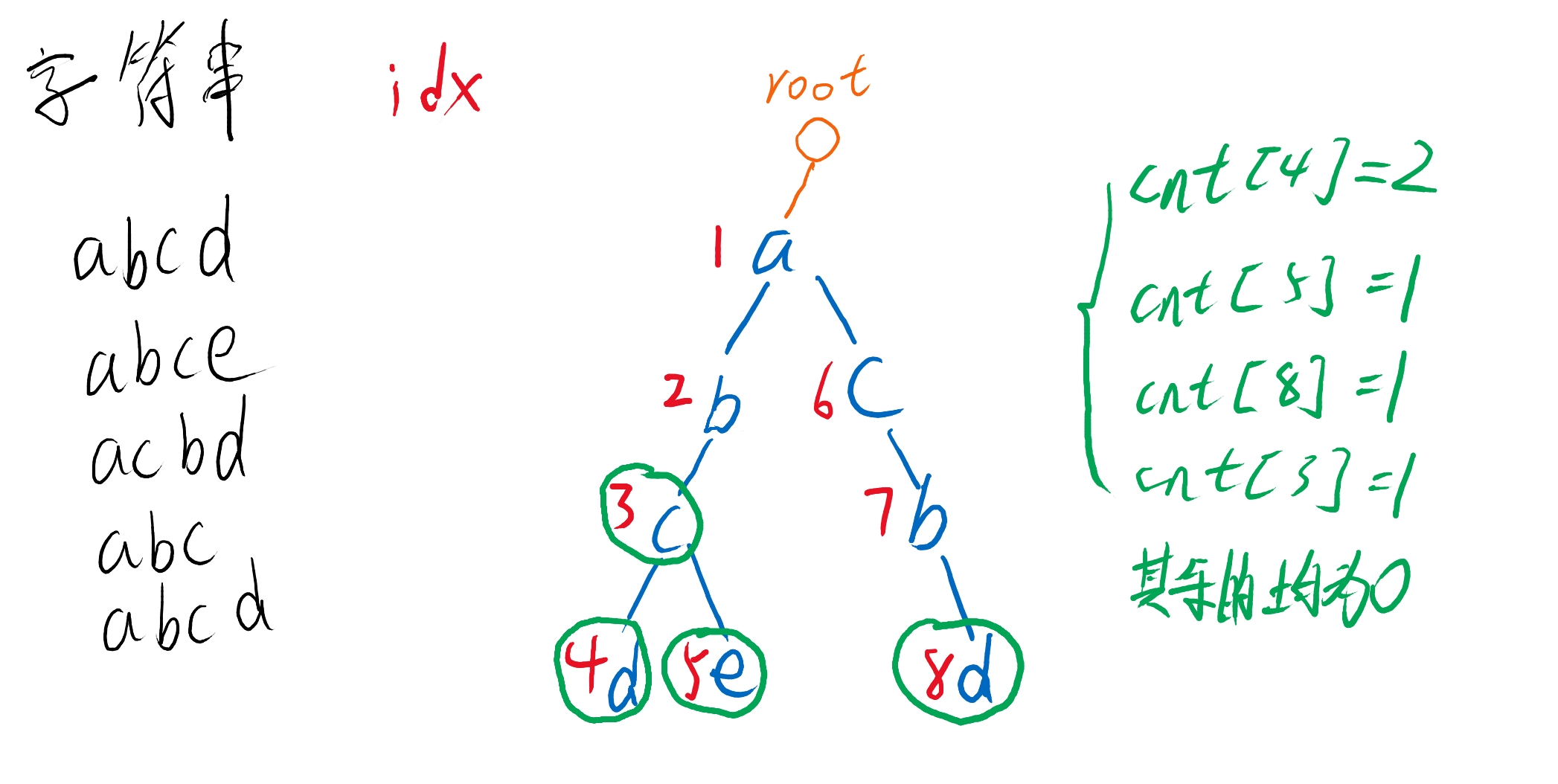
代码
#include<iostream>
using namespace std;
//son[][]存储子节点的位置,分支最多26条;
//cnt[]存储以某节点结尾的字符串个数(同时也起标记作用)
//idx表示当前要插入的节点是第几个,每创建一个节点值+1
const int N = 1e6+10;
int son[N][26],cnt[N],idx;
char str[N];
//插入操作
void insert(char str[])
{
int p=0;//类似指针,指向字符串开头
for(int i=0;str[i];i++)
{
int u=str[i]-'a';
if(!son[p][u]) son[p][u]=++idx;
p=son[p][u];
}
cnt[p]++;
}
//查询操作
int query(char str[])
{
int p=0;
for(int i=0;str[i];i++)
{
int u=str[i]-'a';
if(!son[p][u]) return 0;
p=son[p][u];
}
return cnt[p];
}
int main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
int n;
cin>>n;
while (n -- )
{
char op;
cin>>op>>str;
if(op=='I')
insert(str);
else
cout<<query(str)<<endl;
}
return 0;
}
