
干货最多的一条,可以收藏后精读细解
AC自动机
AC自动机可以说是KMP算法的多模式匹配版,用模式串$pat$匹配主串$txt$是KMP,用模式串列表$patList$中的每个元素匹配$txt$就是AC自动机,这个列表可以用字典树($Trie$)来更高效的表示。KMP和$Trie$不再细说,直接进入AC自动机的特化部分,首先来看字典树节点的成员:(由于不需要第三方库调用,以下代码中默认在std命名空间之下)
struct TrieNode {
int end = 0; //以该节点对应字符结束的字符串数量
bool visit = false; //访问位,记录AC自动机统计过程中是否被访问过
unordered_map<char, TrieNode*> child; //后继节点指针表,一个节点对应一个字符
TrieNode* fail; //AC自动机专用失配指针,在匹配失败后找到合适的位置继续匹配(类似于KMP算法中的nxt数组)
};
可以看出相比一般的字典树节点,多了一个访问位和一个$fail$指针,先来说这个$fail$指针,它就相当于KMP算法中的$nxt$表,可以找到当前位置失配后继续从哪个位置开始匹配,和KMP不同的是,AC自动机寻找的是模式串的相同前缀。
然后,我们在$Trie$类之上,构建AC自动机,先给出$Trie$类声明:
class Trie {
private:
//字典树的根节点
TrieNode* root;
//设置所有节点的fail指针
void setFail();
public:
//构造函数,在此之中一次性插入所有模式串并设置fail指针,此后不再新增模式串
Trie(int n);
//插入模式串
void insertPattern(string pat);
//统计主串中模式串的出现次数
int countFrequency(string text);
};
然后是构造函数:
Trie::Trie(int n) //相当于构造长度为n的字符串列表patList,一次性输入所有pat串
{
root = new TrieNode;
//输入每一条pat
string pat;
while (n--) {
cin >> pat;
insertPattern(pat);
}
//一次性设置所有fail,此后暂时不增加pat
setFail();
}
插入模式串的成员函数$insertPattern$和一般字典树没有太大差别,可以直接套用:
void Trie::insertPattern(string pat)
{
TrieNode* cur = root;
for (auto& ch : pat) {
if (cur->child.find(ch) == cur->child.end()) {
cur->child[ch] = new TrieNode;
}
cur = cur->child[ch];
}
cur->end++;
}
然后是基于BFS的fail指针设置函数$setFail$,其中含有三条明确规则和一条隐性规则,请见注释:
void Trie::setFail()
{
//基于BFS设置fail指针
//第0条规则:根节点的fail指针是null
queue<TrieNode*> noFail;
TrieNode* cur = root;
noFail.push(cur);
while (!noFail.empty()) {
cur = noFail.front();
noFail.pop();
for (auto& [ch, node] : cur->child) {
if (!node) continue;
if (cur == root) {
//第一条规则:根节点的孩子节点,fail指针全部指向根节点
node->fail = root;
}
else {
TrieNode* nxt = cur->fail;
while (nxt) {
//第二条规则:沿着fail指针一路回溯
//如果孩子节点中有与当前字符相同的代表节点,就用fail指针把两者连接起来
if (nxt->child.find(ch) != nxt->child.end()) {
node->fail = nxt->child[ch];
break;
}
else {
nxt = nxt->fail;
}
}
//第三条规则,如果一路上都没有发现相同字符,则把fail指针指向根节点
if (!nxt) node->fail = root;
}
noFail.push(node);
}
}
}
附上两张图,看一下具体到某个节点的fail指针设置过程,以及全部fail指针设置完成后的字典树
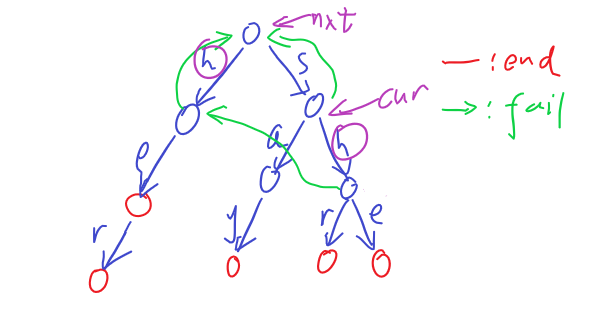
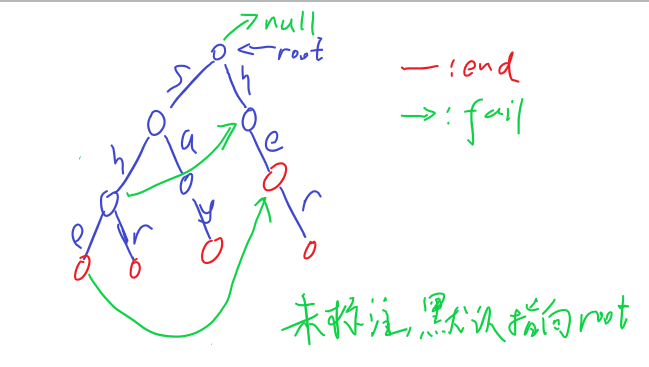
最后是统计模式串出现频数的成员函数$countFrequency$,详情也在注释里
int Trie::countFrequency(string text)
{
int ans = 0;
TrieNode* cur = root, * node = nullptr;
for (auto& ch : text) {
//当前节点的孩子节点中没有字符ch代表的子节点即失配,需要沿着fail指针重新匹配
while (cur->child.find(ch) == cur->child.end() && cur != root) {
cur = cur->fail;
}
if (cur->child.find(ch) != cur->child.end()) cur = cur->child[ch];//匹配成功就进入对应子节点
if (!cur) cur = root;
node = cur;
//node是根节点就代表完全失败
while (node != root) {
//如果没有被统计过,且某个节点代表着属于某个pat串的结尾,就加上它作为结尾出现的次数end
if (!node->visit) {
ans += node->end;
node->end = 0;
//将访问位置为true,防止重复统计
node->visit = true;
}
else break;
node = node->fail;
}
}
return ans;
}
同样上图:
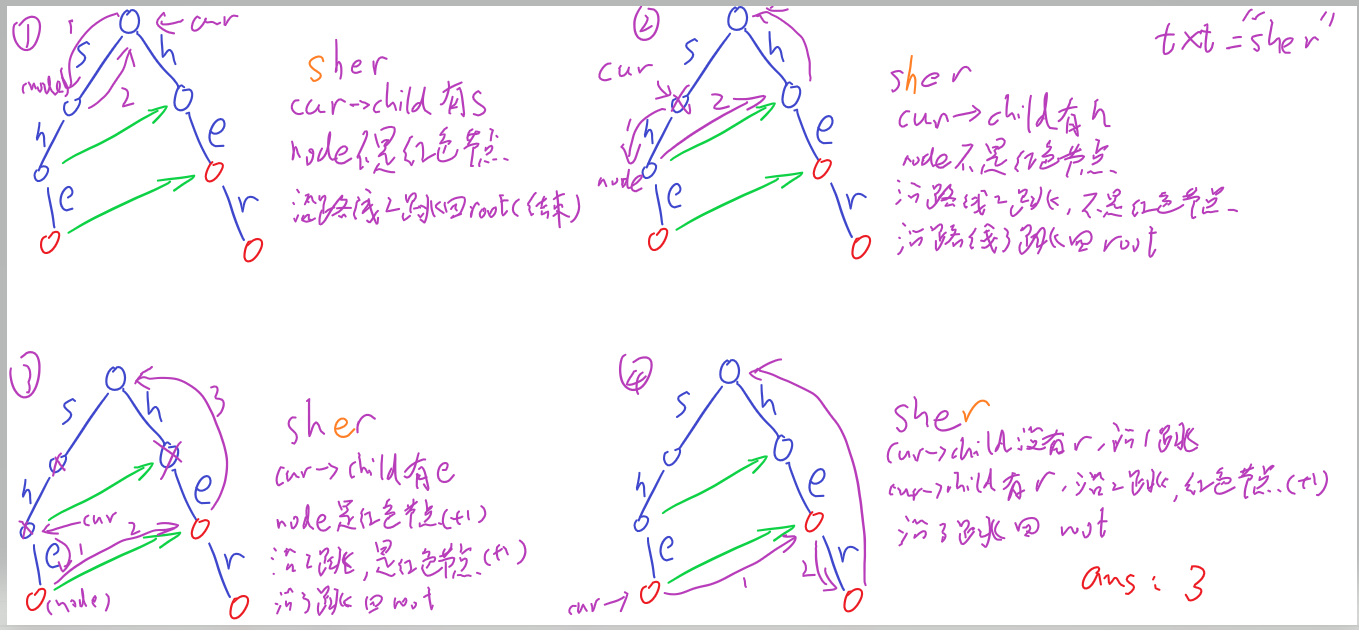
至此,基本原理已解释完毕,但是注意到一件事:测试用例包含多组!
为防止整蛊一样的出现超大组数,在此我们单例模式,启动!
class Singleton {
private:
//内部类,专门回收instance内存
class MemoryCollector {
public:
~MemoryCollector() {
if (instance != nullptr) {
delete instance;
instance = nullptr;
}
}
};
//类外不能调用构造、析构函数
Singleton() {}
~Singleton() {}
static Singleton* instance;
static MemoryCollector collector;
public:
//静态函数,获取类的唯一实例
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
};
//静态成员变量需要在外部初始化
Singleton* Singleton::instance = nullptr;
Singleton::MemoryCollector Singleton::collector;
以上就是一个懒汉单例模式的模板,将单例模式用于本问题中的$Trie$类,可以保证程序运行过程中,$Trie$类的实例只有一个,在含有多组测试用例时可以减少new/delete次数,并且可以复用同样的内存
在此基础上还可以继续改造,毕竟直接用指针,调用了那么多次new,delete起来挺麻烦的,一种方式是使用索引式,将指针全部改为索引类型_Idx(可以 using _Idx = int; ),还有就是使用智能指针,不过后一种办法可能涉及深浅拷贝,需要丰富的C++编程经验,考虑到本站用户大多数是像我一样还在求学的学生,对此概念尚未烂熟于心,就使用第一种办法索引式,并将全部代码贴在下方,如果有想看智能指针+深拷贝的,问题1285中会尝试使用此方法
C++ 完整代码
#include <iostream>
#include <algorithm>
#include <string>
#include <unordered_map>
#include <vector>
#include <queue>
using namespace std;
using _Idx = int;//自定义索引类型(也可用size_t,用limit.h中的ULLONG_MAX判空)
struct TrieNode {
bool visit = false;
int end = 0;
//指针改为索引,移动到某个节点时直接查找对应的索引即可
unordered_map<char, _Idx> childIdx;
_Idx fail = -1;//-1代表空节点,根节点默认初始化之后不再参与修改
};
//融入单例模式的字典树类Trie
class Trie {
private:
class GarbageCollector {
public:
~GarbageCollector() {
if (instance != nullptr) {
delete instance;
instance = nullptr;
}
}
};
vector<TrieNode> base;//为了配合索引的使用,将所有节点全部存入线性表
_Idx insIdx = 0;//根节点的索引永远为0
static Trie* instance;
static GarbageCollector gc;
Trie() {
base.push_back(TrieNode());
}
~Trie() {}
void setFail() {
queue<_Idx> noFail;//队列存放的也是索引
_Idx cur = 0;
noFail.push(cur);
//第0条规则,在根节点初始化的时候就体现了
while (!noFail.empty()) {
cur = noFail.front();
noFail.pop();
for (auto& [ch, id] : base[cur].childIdx) {
if (id < 1) continue;
//对应第一条规则:根节点的孩子,fail索引全部都为0(根)
if (cur == 0) {
base[id].fail = cur;
}
else {
_Idx pos = base[cur].fail;
while (pos != -1) {
//对应第二条规则,索引pos的节点的子节点中有相同代表节点,则当前节点的fail索引就指向它
if (base[pos].childIdx.find(ch) != base[pos].childIdx.end()) {
base[id].fail = base[pos].childIdx[ch];
break;
}
pos = base[pos].fail;
}
//对应第三条规则,如果一直没有找到相同代表节点,就把fail索引置为0
if (pos == -1) base[id].fail = 0;
}
noFail.push(id);
}
}
}
public:
static Trie* getInstance(int n = 0) {
if (instance == nullptr) {
instance = new Trie;
}
//存放节点用的线性表可以复用,不用每次都重新构造
instance->insIdx = 0;
//记得清空上一次的记录
fill(instance->base.begin(), instance->base.end(), TrieNode());
string word;
//将构造函数里要做的事放到getInstance里边
while (n--) {
cin >> word;
instance->insertWord(word);
}
if(n != 0) instance->setFail();
return instance;
}
void insertWord(string word) {
_Idx cur = 0;
for (char c : word) {
if (base[cur].childIdx.find(c) == base[cur].childIdx.end()) {
/*
* 插入节点的时候作此改动,用一个索引值控制插入位置
* 新构造的节点的索引就是该索引值自身
* 只有在base表满的时候,才需要调用push_back
* 否则就在索引insIdx处直接复制构造节点
* 节点中不含有指针,没有深浅拷贝问题
* 占用的空间就只和单组测试用例中节点的最大数量有关了
*/
insIdx++;
if (insIdx == base.size()) { //插入位置索引在base的下标范围之外,就代表满了
base.push_back(TrieNode());
}
else {
base[insIdx] = TrieNode();
}
base[cur].childIdx[c] = insIdx;
}
cur = base[cur].childIdx[c];
}
base[cur].end++;
}
//类似的,所有指针都改为索引
int countFrequency(string text) {
int ans = 0;
_Idx cur = 0, pos = -1;
for (auto ch : text) {
while (base[cur].childIdx.find(ch) == base[cur].childIdx.end()
&& cur != 0) {
cur = base[cur].fail;
}
if (base[cur].childIdx.find(ch) != base[cur].childIdx.end()) {
cur = base[cur].childIdx[ch];
}
pos = cur;
while (pos != 0) {
if (!base[pos].visit) {
ans += base[pos].end;
base[pos].end = 0;
base[pos].visit = true;
}
else break;
pos = base[pos].fail;
}
}
return ans;
}
};
//类外的全局区进行静态变量默认初始化
Trie* Trie::instance = nullptr;
Trie::GarbageCollector Trie::gc;
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
int t, n;
string text;
Trie* trie = nullptr;
cin >> t;
while (t--) {
cin >> n;
trie = Trie::getInstance(n);
cin >> text;
cout << trie->countFrequency(text) << endl;
}
/*
* 程序结束后会自动调用Trie类内GarbageCollector的析构函数
* 静态指针变量instance由此析构,可以回收所有堆区内存
* 用饿汉单例模式可以不用担心内存的释放问题,1285中会尝试使用
*/
return 0;
}