
循环节
原问题是对于 $S_1 = [s_1, \ n_1]$ 和 $S_2 = [s_2, \ n_2]$,求最大的整数 $m$,使得 $S = [S_2, \ m]$ 为 $S_1$ 的子序列。
问题可转化为求 $S_1 = [s_1, \ n_1]$ 中含有多少个 $s_2$(不足一整个串就不算),记为 $cnt$,答案 $m = \lfloor \frac{cnt}{n_2} \rfloor$。
但根据数据范围,$S_1$ 太长,最长可到 $10^8$,所以不可能是直接遍历(要是 $cf$ 神机感觉有希望哈哈)。
既然不能遍历整个 $S_1$,那么就可以考虑把某段区间的遍历操作压缩至 $O(1)$ 或 $O(logn)$,例如倍增和循环节,而这里由于 $s_1$ 和 $s_2$ 的长度小,因此可以考虑循环节。
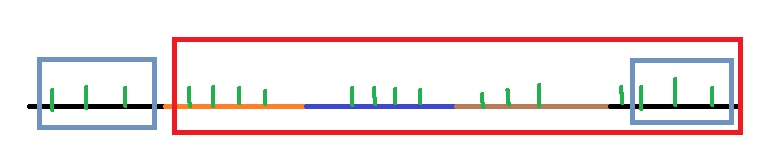
想象一个上图是一个很长很长的 $s_1$ 循环串,接下来就以上图为例子进行说明。
第一个 $s_1$ 匹配 $s_2$ 的前 $3$ 个字符,第二个 $s_1$ 再从这个前缀之后开始匹配,匹配到 $4$ 个字符,以此类推。
其中绿色表示 $s_1$ 中与 $s_2$ 的字符按顺序匹配上的地方,两个蓝色方框框住的是 $s_2$ 的前 $3$ 个字符,红色方框表示循环节(注意循环节里含有的匹配字符数可能是 $s_2$ 长度的若干倍)。
于是我们再换个角度考虑,也就是从单个字符匹配出发,计算 $S_1$ 匹配了多少字符,记为 $tot$,则 $S_1$ 中含有 $s_2$ 的数量 $cnt = \lfloor \frac{tot}{s_2.size()} \rfloor$。
为了找出循环节,要记录每个 $s_1$ 匹配到的 $s_2$ 的位置。当发现第 $i$ 个 $s_1$ 与 $s_2$ 匹配后,停留在 $s_2$ 的位置出现过的时候,设上一个停留在这个位置的 $s_1$ 的是第 $j$ 个 $s_1$ ,那么循环节就是 $i - j$ 个 $s_1$。
这样一来循环节就找到了,同时根据匹配到的 $s_2$ 的位置,也能知道循环节内含有的(绿色)匹配字符数。
最后别忘了末尾还可能有不完整的循环节,需要再遍历一次。
时间复杂度 $O(s_1.size() \times s_2.size())$
C++ 代码
class Solution {
public:
int getMaxRepetitions(string s1, int n1, string s2, int n2) {
int n = s1.size(), m = s2.size();
map<int, int> h; // 记录停留位置 p 对应的是第几个 s1
vector<int> cnt; // 记录第 i 个 s1 匹配后 s2 的停留位置
int tot = 0; // 总共含有的匹配字符数
for (int i = 0, k = 0; i < n1; i += 1) {
for (int j = 0; j < n; j += 1) {
if (s1[j] == s2[k % m]) {
k += 1;
}
}
tot = k;
cnt.push_back(k);
int r = k % m;
if (h.count(r)) {
int lst = h[r]; // 上一个停留在 r 的是第 lst 个 s1
int c1 = i - lst; // 循环节含有 c1 个 s1
int c2 = k - cnt[lst]; // 循环节含有 c2 个匹配字符
tot += (n1 - i - 1) / c1 * c2;
for (int j = 0; j < (n1 - i - 1) % c1; j += 1) { // 最后一段不完整的循环节
for (int u = 0; u < n; u += 1) {
if (s1[u] == s2[k % m]) {
k += 1;
tot += 1;
}
}
}
break;
}
h[r] = i;
}
return tot / m / n2;
}
};
