
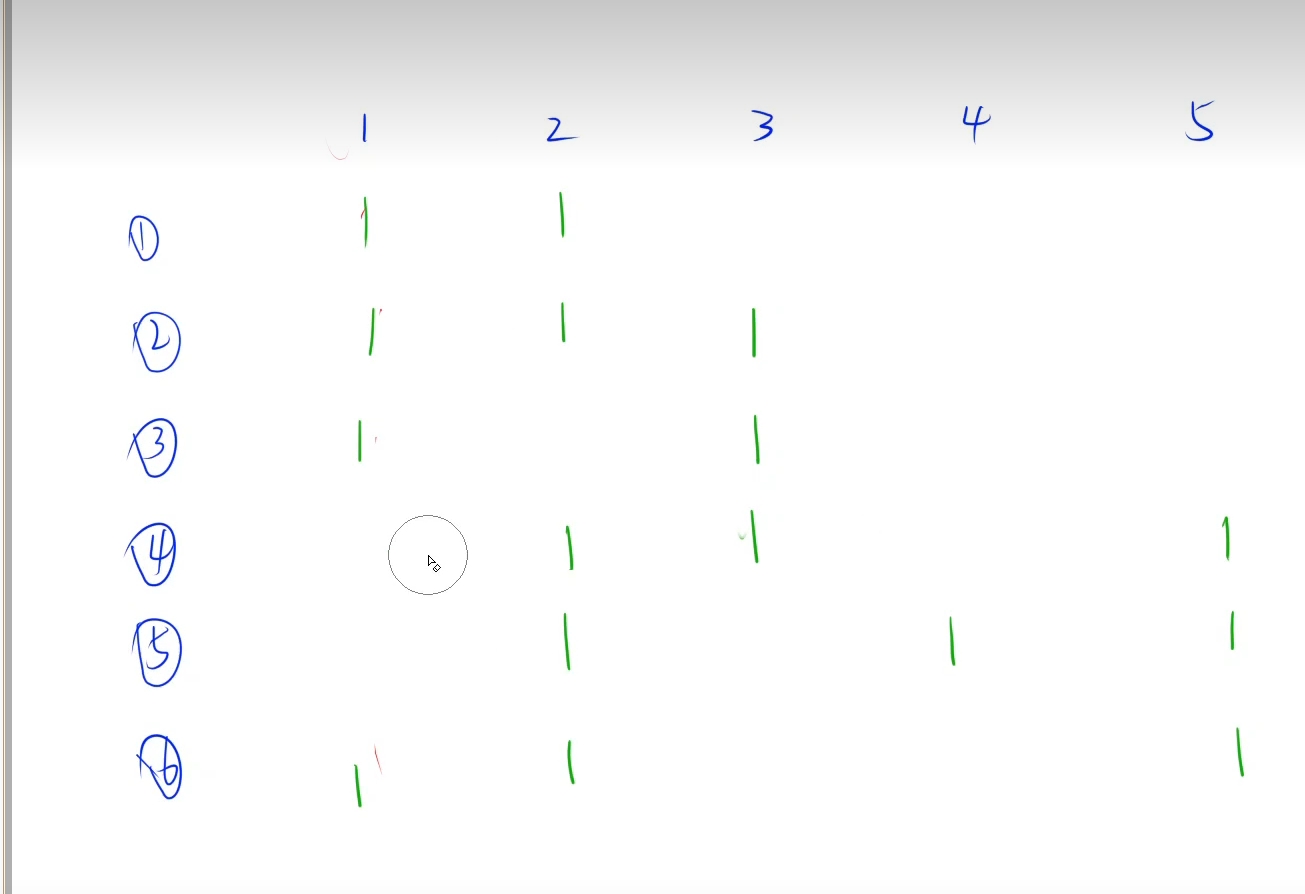
1.样例展示
n包糖果表示行,m种口味表示列
2.本题优化方法

其中1和3方法合起来叫做IDA算法(深搜版的A算法)
3.代码实现
#include<iostream>
#include<algorithm>
#include<cstring>
#include<vector>
using namespace std;
const int N = 110, M = 1 << 20;
int n, m, k;
//n为行的数量(n包糖果),m为列的数量(口味有多少就有多少列),k为每包糖的数量
int log2[M]; //存储以2为底的数的值,例如log2[2] = 1;
vector<int> col[N]; //col[]来存储哪些行可以包含这一列
int lowbit(int x)
{
return x & -x;
}
int h(int state) //h()函数来计算至少还要再选多少行
{
int res = 0;
for (int i = (1 << m) - 1 - state; i; i -= lowbit(i))
{
int c = log2[lowbit(i)];
res ++;
for (auto row : col[c]) i &= ~row;
//由于i=(1<<m)-1-state,当前的i中1表示的是没选的列,0表示的是选过的列
//row取反之后,1表示该行不能覆盖该列,0表示的是该行能覆盖该列
//0&0为0,选过+能覆盖,第i列还是选过的列,为0
//0&1为0,选过+不能覆盖,第i列还是选过的列,为0
//1&0为0,没选过+能覆盖,第i列变为选过的列,为0
//1&1为1,没选过+不能覆盖,第i列还是没有选过的列,为1
}
return res;
}
bool dfs(int depth, int state)
{
// 判断不能再选的情况,此时还要判断是否已经把m列都选掉了(state是否是m个1)
if(!depth || h(state) > depth) return state == (1 << m) - 1;
// 找到选择性最少的一列
int t = -1;
for(int i = (1 << m) - 1 - state; i; i -= lowbit(i)) //用m个1减去当前状态,如果某位还为1代表该列没被选上
{
int c = log2[lowbit(i)];
if(t == -1 || col[t].size() > col[c].size())
t = c;
}
// 枚举选哪行
for(auto row : col[t])
if(dfs(depth - 1, state | row))
return true;
return false;
}
int main()
{
cin >> n >> m >> k;
for(int i = 0; i < m ; i ++) log2[1 << i] = i; //预处理log2数组
for(int i = 0 ; i < n; i ++)
{
int state = 0;
for(int j = 0; j < k ; j ++)
{
int c;
cin >> c;
state |= 1 << c - 1; //将这一位变成1,注意先算'-'再算'<<'
//我们把口味编号变成 0 ~ m - 1
}
for(int j = 0 ; j < m ; j ++) //枚举每一列
if(state >> j & 1) //如果当前这行包含j这列,加入vector中
col[j].push_back(state);
}
for (int i = 0; i < m; i ++ ) //将重复的行删掉,剪枝
{
sort(col[i].begin(), col[i].end());
col[i].erase(unique(col[i].begin(), col[i].end()), col[i].end());
}
//迭代加深
int depth = 0;
while(depth <= m && !dfs(depth, 0)) depth ++;
//最多选m行,因为有m种口味(即m列),每行包含一列,m行也就够了
if(depth > m) depth = -1; //选择超过m行无解
cout << depth << endl;
return 0;
}
