
<—点个赞吧QwQ
宣传一下算法提高课整理{:target=”_blank”}
Dinic算法
本题解将会介绍另一种网络流算法,在二分图问题上比EK算法高效,先说怎么构造二分图和网络流模型:
把行列数都为$n$的矩阵中,每一个格子看成一个图节点,如果一个格子上可以放骨牌,由于骨牌的长度是2,宽度是1,刚好可以覆盖相邻的两个格子,相当于这两个节点被匹配了,同时还可以发现,这一对匹配节点中,其中一个行列号之和是偶数,另一个行列号之和是奇数,只需要把行列号之和为奇数的格子代表的节点连向它四周的格子代表的节点,二分图就构造完毕了
构造网络流则要在此基础上添加公共始端和公共终端,我们让公共始端连向行列号之和为奇数的节点,然后让公共终端被行列号为偶数的节点所连接,网络流模型就构造完毕了,就像图中的这样
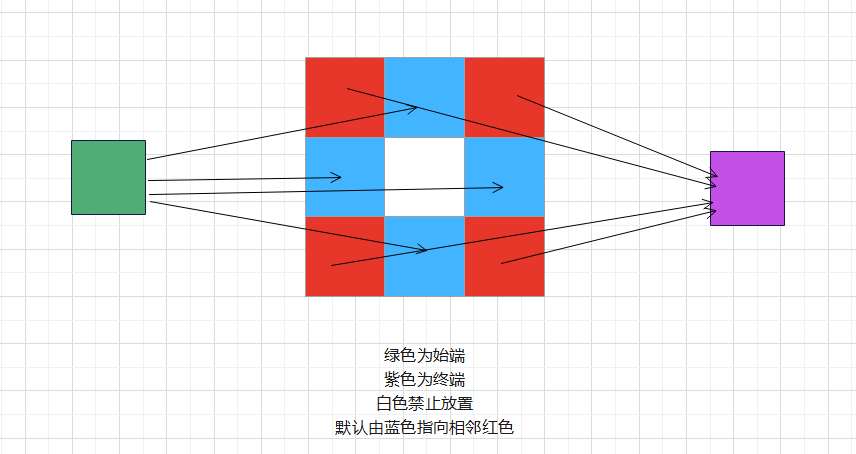
二维坐标转化为一维索引需要用到矩阵的行优先存储,转化完毕之后可以发现节点总数为$n^2$,$n$最大值为100的话,节点总数可以达到$10^4$数量级,光是这一点,基于邻接矩阵存储的EK算法就行不通了,因此,它需要时间和空间上都更高效的算法,那么就来到了这次的重点:Dinic算法
Dinic算法的两个关键:分层增广,不能越级
先说“分层增广”,指的是查找增广路时需要对每个节点赋予层级,在遍历到某个节点$u$时,对于它的每一个后继节点$v$,只要$v$没有被遍历过,并且到达$v$的边容量大于0,就可以为$v$赋予层级,判断是否增广成功的标准就是从始端出发,能否为终端赋予层级。增广的过程,毫无疑问就是基于BFS的了
再说“不能越级”,是指每个节点都只能直接往它的下一层级的节点发送流量,不存在层级为$d$的节点往层级为$d+2$及更高层级的节点发送流量的情况,这个时候如果要求最大流量,就需要基于DFS,从终端向前回溯,对于非终端节点的每个节点,都需要先计算出它后继节点能发送的流量,再累加到当前节点发送的流量中。由于增广时不再关心增广的具体路径,只关心结果,因此Dinic算法的一次增广可以相当于EK算法的多次增广,本身在边比较多的时候就比EK算法有优势了
但是使用常规的Dinic算法,在这个问题中仍然会TLE,这里我们可以再加一个小技巧,先来说说为什么:
Dinic算法跟EK算法一样,发送流量的时候,必然会有一条边达到饱和状态,就像下图所示:
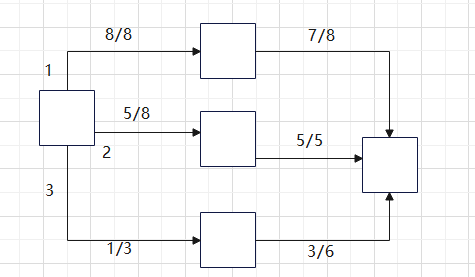
这时候,图上标出的边1,2,对应的路径都饱和了,可以视作这个边1,2也处于饱和(saturated)状态,仅剩下边3未饱和,因此我们额外用一张表,来记录按照遍历顺序,每个节点的出边中最先出现的未饱和(unsaturated)边是哪条,这样的话,发送流量时可以跳过那些饱和边,省去一些递归时间
详细细节请见注释,另外一定有细心的网友发现了,我用链式前向星存储图时,明明tot代表的是已经连上的边总数,为什么初始值要设为2,对于这个,在注释中同样有解释
时间复杂度
$O(\sqrt{n}\*m)$,$n,m$分别为节点数和边数
这是二分图问题上,Dinic算法的特有理论复杂度,一般图上Dinic算法的复杂度则为$O(n^2\*m)$
C++ 代码
#pragma GCC optimize(2)
#include <iostream>
#include <algorithm>
#include <queue>
#include <functional>
using namespace std;
const int N = 1e4 + 5, M = 6 * N, inf = 1e9 + 7;
int fin[M], val[M], last[N], nxt[M], depth[N];//链式前向星存储时,需要按行优先将二维坐标降维
//小技巧,记录从某节点出发,第一条未饱和(unsaturated)的边序号
int unsaturated[N];
int tot = 2, ans = 0;//此代码注释中将会介绍到,为什么此tot用来表示边被连接上的次序,初始值却要设为2
int banned[105][105];//不能放骨牌的坐标仍然采用二维形式
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n, m;
cin >> n >> m;
//总共n*n个节点,公共始端序号为0,公共终端序号为(节点总数+1)
int source = 0, terminal = n * n + 1;
while (m--) {
int s, e;
cin >> s >> e;
banned[s][e] = 1;//不能放骨牌
}
//行优先存储的索引
auto key = [=](int x, int y)-> int {
return (x - 1) * n + y;
};
//单,双向连接函数
auto _connect = [=](int s, int e, int v) {
fin[tot] = e;
val[tot] = v;
nxt[tot] = last[s];
last[s] = tot++;
};
auto connect = [=](int s, int e) {
//双向连接时正向容量1反向容量0,两条边序号紧挨
_connect(s, e, 1);
_connect(e, s, 0);
};
//开始构建二分图
int dx[4] = { 1,0,-1,0 }, dy[4] = { 0,1,0,-1 };
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (banned[i][j] == 1) continue;
if ((i + j) % 2 == 1) {
for (int k = 0; k < 4; k++) {
int x = i + dx[k], y = j + dy[k];
//跳过出界的和禁止放置的
if (x < 1 || x > n || y < 1 || y > n || banned[x][y] == 1) continue;
connect(key(i, j), key(x, y));
}
connect(source, key(i, j));
}
else connect(key(i, j), terminal);
}
}
//增广路查找函数
auto findPath = [=](int source, int terminal)->bool {
queue<int> q;
fill(depth, depth + N, -1);
q.push(source);
depth[source] = 1;
//查找增广路时,last表可以复制给未饱和边表
copy(last, last + N, unsaturated);
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = last[cur]; i != 0; i = nxt[i]) {
int nx = fin[i];
//后继节点未访问,且当前经过边的容量大于0,就访问它
if (depth[nx] == -1 && val[i] > 0) {
depth[nx] = depth[cur] + 1;
//类似于EK算法,提前结束(也因此,队列q需要放在函数内)
if (nx == terminal) return true;
q.push(nx);
}
}
}
return false;
};
//往终端发送流量
function<int(int, int, int)> sendFlow =
[&sendFlow](int cur, int terminal, int rest)->int {
if (cur == terminal) return rest;//到达终端了
int sum = 0;
//从第一条未饱和边开始搜索
for (int i = unsaturated[cur]; i != 0; i = nxt[i]) {
unsaturated[cur] = i;//更新未饱和边表,代表着前面的几条边都饱和了
int nx = fin[i];
//流量只能发送往相邻的层级,不能越级
if (depth[nx] == depth[cur] + 1 && val[i] > 0) {
/*
* 后继节点发送的流量有两个条件:
* 1、需要在剩余可发送流量rest中减去当前节点已发送的流量sum
* 2、后继节点可发送的最大流量,不能比到达该节点所经过的边容量还大
*/
int mf = sendFlow(nx, terminal, min(val[i], rest - sum));
if(mf == 0) depth[nx] = -1;//饱和了的话,后续就不用再搜索它了,进一步剪枝
/*
* 至此大概可以发现tot初值为2的好处了
* 既然正反双向的边序号紧挨着
* 那么如果正向边序号是偶数,反向边序号在此基础上+1,异或1之后就可以互相转换
* 而tot初值如果是1,那么正向边序号是奇数,取反向边容易搞错
*/
val[i] -= mf;
val[i ^ 1] += mf;
sum += mf;
if (mf == rest) return mf;//此时代表着整体网络流达到饱和状态,也可以提前结束
}
}
return sum;
};
//Dinic算法的核心所在
while (findPath(source, terminal)) {
ans += sendFlow(source, terminal, inf);
}
cout << ans << endl;
return 0;
}
