
题目描述
给你一个下标从 0 开始、大小为 n x n 的二维矩阵 grid,其中 (r, c) 表示:
- 如果
grid[r][c] = 1,则表示一个存在小偷的单元格 - 如果
grid[r][c] = 0,则表示一个空单元格
你最开始位于单元格 (0, 0)。在一步移动中,你可以移动到矩阵中的任一相邻单元格,包括存在小偷的单元格。
矩阵中路径的 安全系数 定义为:从路径中任一单元格到矩阵中任一小偷所在单元格的 最小 曼哈顿距离。
返回所有通向单元格 (n - 1, n - 1) 的路径中的 最大安全系数。
单元格 (r, c) 的某个 相邻 单元格,是指在矩阵中存在的 (r, c + 1)、(r, c - 1)、(r + 1, c) 和 (r - 1, c) 之一。
两个单元格 (a, b) 和 (x, y) 之间的 曼哈顿距离 等于 | a - x | + | b - y |,其中 |val| 表示 val 的绝对值。
样例
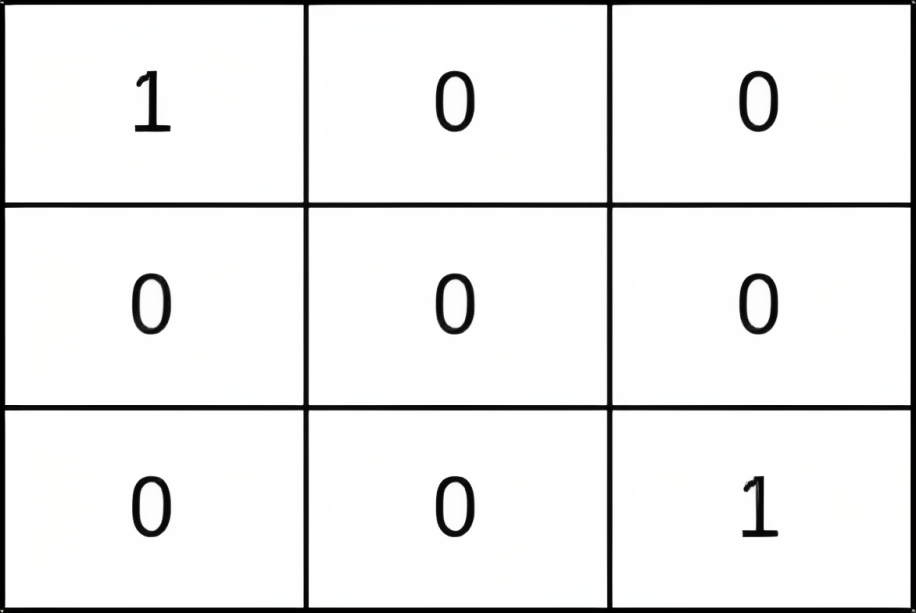
输入:grid = [[1,0,0],[0,0,0],[0,0,1]]
输出:0
解释:从 (0, 0) 到 (n - 1, n - 1) 的每条路径都经过存在小偷的单元格 (0, 0) 和 (n - 1, n - 1)。
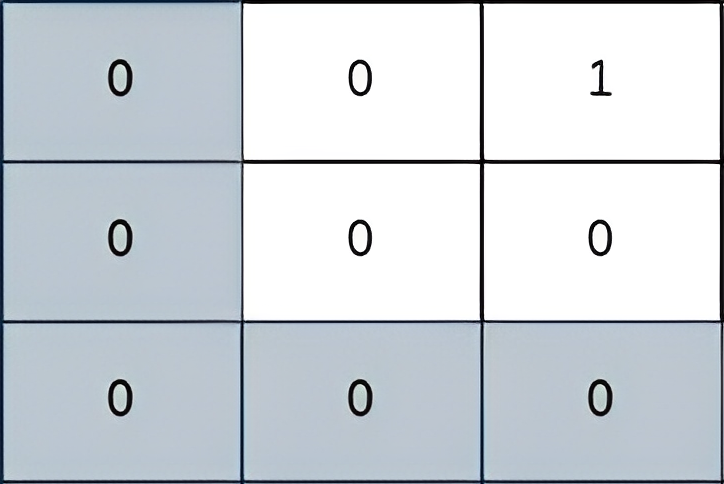
输入:grid = [[0,0,1],[0,0,0],[0,0,0]]
输出:2
解释:
上图所示路径的安全系数为 2:
- 该路径上距离小偷所在单元格(0,2)最近的单元格是(0,0)。
它们之间的曼哈顿距离为 | 0 - 0 | + | 0 - 2 | = 2。
可以证明,不存在安全系数更高的其他路径。
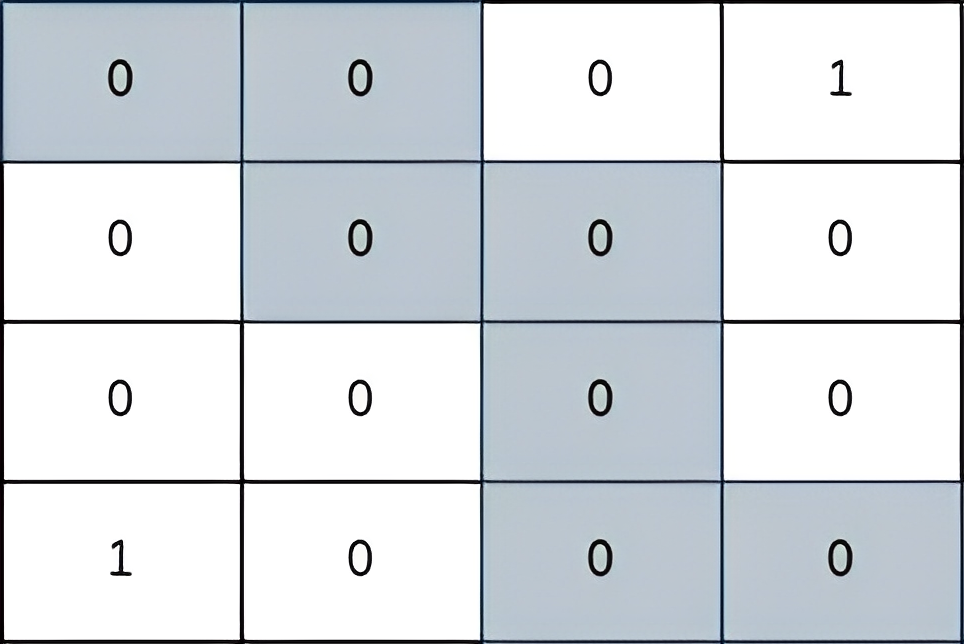
输入:grid = [[0,0,0,1],[0,0,0,0],[0,0,0,0],[1,0,0,0]]
输出:2
解释:
上图所示路径的安全系数为 2:
- 该路径上距离小偷所在单元格(0,3)最近的单元格是(1,2)。
它们之间的曼哈顿距离为 | 0 - 1 | + | 3 - 2 | = 2。
- 该路径上距离小偷所在单元格(3,0)最近的单元格是(3,2)。
它们之间的曼哈顿距离为 | 3 - 3 | + | 0 - 2 | = 2。
可以证明,不存在安全系数更高的其他路径。
限制
1 <= grid.length == n <= 400grid[i].length == ngrid[i][j]为0或1。grid至少存在一个小偷。
算法1
(宽度优先遍历,二分答案) $O(n^2 \log n)$
- 通过宽度优先遍历,预处理每个点距离小偷的最短距离。
- 二分最终的安全系数,宽度优先遍历判断在当前安全系数下是否存在一条路径。
时间复杂度
- 预处理的时间复杂度为 $O(n^2)$。
- 二分的上下界为 $O(n)$,每次判定的时间复杂度为 $O(n^2)$。
- 故总时间复杂度为 $O(n^2 \log n)$。
空间复杂度
- 需要 $O(n^2)$ 的额外空间存储预处理的距离数组,宽度优先遍历的队列。
C++ 代码
const int dx[] = {0, 1, 0, -1};
const int dy[] = {1, 0, -1, 0};
const int N = 410;
class Solution {
private:
int n, d[N][N];
bool v[N][N];
queue<int> q;
void bfs(const vector<vector<int>> &grid) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) {
d[i][j] = INT_MAX;
if (grid[i][j] == 1) {
q.push(i * n + j);
d[i][j] = 0;
}
}
while (!q.empty()) {
int ux = q.front() / n, uy = q.front() % n;
q.pop();
for (int i = 0; i < 4; i++) {
int x = ux + dx[i], y = uy + dy[i];
if (x < 0 || x >= n || y < 0 || y >= n)
continue;
if (d[x][y] > d[ux][uy] + 1) {
d[x][y] = d[ux][uy] + 1;
q.push(x * n + y);
}
}
}
}
bool check(int m, const vector<vector<int>> &grid) {
memset(v, false, sizeof(v));
q.push(0);
v[0][0] = true;
while (!q.empty()) {
int ux = q.front() / n, uy = q.front() % n;
q.pop();
for (int i = 0; i < 4; i++) {
int x = ux + dx[i], y = uy + dy[i];
if (x < 0 || x >= n || y < 0 || y >= n || v[x][y])
continue;
if (d[x][y] >= m) {
v[x][y] = true;
q.push(x * n + y);
}
}
}
return v[n - 1][n - 1];
}
public:
int maximumSafenessFactor(vector<vector<int>>& grid) {
n = grid.size();
bfs(grid);
int l = 0, r = d[0][0];
while (l < r) {
int mid = (l + r) >> 1;
if (check(mid + 1, grid)) l = mid + 1;
else r = mid;
}
return l;
}
};
算法2
(宽度优先遍历,并查集) $O(n^2)$
- 通过宽度优先遍历,预处理每个点距离小偷的最短距离。
- 按照距离从大到小遍历每个位置,假设当前距离为 $d$,可以把这个位置与四周位置距离大于等于 $d$ 的位置通过并查集合并起来,然后使用并查集判断 $(0, 0)$ 到 $(n - 1, n - 1)$ 是否连通。
- 如果连通,则立刻返回 $d$ 作为答案。
时间复杂度
- 预处理的时间复杂度为 $O(n^2)$。
- 并查集单次操作的时间复杂度近似为常数。
- 故总时间复杂度为 $O(n^2)$。
空间复杂度
- 需要 $O(n^2)$ 的额外空间存储预处理的距离数组和并查集数据结构。
C++ 代码
const int dx[] = {0, 1, 0, -1};
const int dy[] = {1, 0, -1, 0};
class Solution {
private:
int n;
vector<vector<int>> d;
vector<pair<int, int>> g;
vector<int> f, sz;
int find(int x) {
return x == f[x] ? x : f[x] = find(f[x]);
}
void merge(int x, int y) {
int fx = find(x), fy = find(y);
if (fx == fy)
return;
if (sz[fx] < sz[fy]) {
f[fx] = fy;
sz[fy] += sz[fx];
} else {
f[fy] = fx;
sz[fx] += sz[fy];
}
}
void bfs(const vector<vector<int>> &grid) {
d.resize(n, vector<int>(n, INT_MAX));
queue<pair<int, int>> q;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
if (grid[i][j] == 1) {
q.push(make_pair(i, j));
d[i][j] = 0;
}
while (!q.empty()) {
auto u = q.front();
q.pop();
g.push_back(u);
for (int i = 0; i < 4; i++) {
int x = u.first + dx[i], y = u.second + dy[i];
if (x < 0 || x >= n || y < 0 || y >= n)
continue;
if (d[x][y] > d[u.first][u.second] + 1) {
d[x][y] = d[u.first][u.second] + 1;
q.push(make_pair(x, y));
}
}
}
}
public:
int maximumSafenessFactor(vector<vector<int>>& grid) {
n = grid.size();
bfs(grid);
f.resize(n * n);
sz.resize(n * n, 1);
for (int i = 0; i < n * n; i++)
f[i] = i;
for (int i = g.size() - 1; i >= 0; i--) {
int x = g[i].first, y = g[i].second;
for (int j = 0; j < 4; j++) {
int tx = x + dx[j], ty = y + dy[j];
if (tx < 0 || tx >= n || ty < 0 || ty >= n)
continue;
if (d[tx][ty] >= d[x][y])
merge(x * n + y, tx * n + ty);
}
if (find(0) == find(n * n - 1))
return d[x][y];
}
return 0;
}
};

想请问一下最后二分时 r = d[0][0]的理由是?我的理解是因为路线必须经过[0][0]点,所以要<=d[0][0], 但是如果换成r=INT_MAX就过不了
可以这样理解。如果改成 r=INT_MAX,需要在check里额外判断下
m > d[0[0]的情况,并直接返回 false多谢老师