
Swin-T
结构与原理
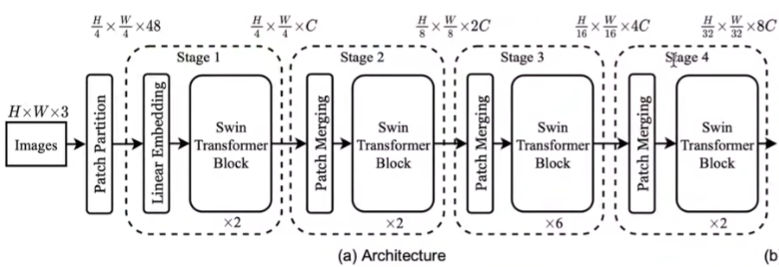
将每张图片划分为4x4的patch,那么共有$\frac{H}{4}*\frac{W}{4}*48$ ,48=channel*4*4。将每个patch对应的token送入后续
patch_merging
随着网络的加深,token的数量要逐渐变少(为了减少复杂度)。第一个patch_merging中就把2x2个patch浓缩成了一个patch,这样patch的数量就减少了4倍,这样embeding长度应该变为原来的4倍,但是这里的C仅仅变为了2倍,是因为embedding进了MLP降为了2倍。
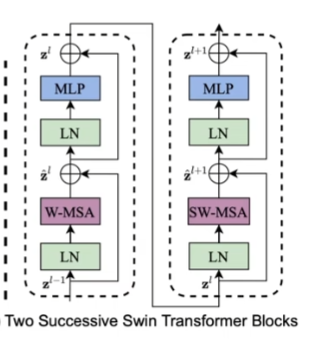
Swin-T block
层归一化+self-attention+MLP
W-MSA:

这里的窗口是这样划分的
SW-MSA:

为了增加不同窗口间的交互信息 (不同patch间的连接性),将每个窗口向下向右移动窗长/2个单位。随着block的增多,近似与可以看完整图片,类似conv。
Tips:
num_patch:通常ViT中,图像会被划分成固定大小的非重叠patch,如果一个8x8的图像被划分成4*4的patch,那么num_patch就是4patch_depth:这是每个 patch 的深度,它等于每个 patch 中的像素数量乘以图像的通道数。继续上面的例子,如果每个 patch 是4x4并且图像有3个通道(例如 RGB),那么patch_depth将会是4*4*3 = 48。
Code
1. 基于图片生成patch embedding
法1:
- pytorch unfold, kernel_size=patch_size
- patch.shape = [bs,num_patch,patch_depth]
- 将shape=[patch_depth,model_dim_C]的权重矩阵做乘法,得到[bs, num_patch, model_dim_C]的patch_embedding
法2:
- patch_depth = in_channel * patch_size * patch_size
- model_dim_C = 二维卷积out_channel
- 将[path_depth, model_dim_C]reshape成[ model_dim_C, in_channel, patch_size, patch_size]的卷积核
- 然后直接卷积得到[bs, out_channel, h, w]
- reshape成[bs, num_patch, model_dim_C]即可
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def image2emb_naive(image, patch_size, weight):
# image.shape = [bs, c, h, w]
# unfold后, shape = [bs, patch_depth, num_patch]
patch = F.unfold(image, kernel_size= (patch_size, patch_size), stride=(patch_size, patch_size)).transpose(-1, -2)
return patch @ weight
def image2emb_conv(image, kernel, stride):
# [bs, C, h, w]
conv_output = F.conv2d(image, kernel, stride=stride)
bs, C, h, w = conv_output.shape
patch_embedding = conv_output.reshape((bs, C, -1)).transpose(-1, -2)
return patch_embedding
2.构建MHSA并计算复杂度
- 基于输入的x进行三个变换得到q,k,v
- 这里复杂度是O($3LC^2$), L=序列长度,C=特征大小
- q,k,v拆成多头形式,这里的多头各自计算不影响,可以与bs维度统一看待
- 计算$qK^T$,并考虑掩码,即让无效的两两位置之间的能量为负无穷,掩码在SW中需要,在W中暂不需要
- 此步复杂度$L^2C$
- 计算概率值与v乘积O($L^2C$)
- 对输出再次映射O($L^2C$)
class MultiHeadSelfAttention(nn.Module):
def __init__(self, model_dim, num_head):
super(MultiHeadSelfAttention, self).__init__()
self.num_head = num_head
# q, k, v一起计算
self.proj_linear_layer = nn.Linear(model_dim, 3*model_dim)
self.final_linear_layer = nn.Linear(model_dim, model_dim)
def forward(self, input, additive_mask=None):
bs, seqlen, model_dim = input.shape
num_head = self.num_head
head_dim = model_dim // num_head
# shape = [bs, seqlen, 3*dim]
proj_output = self.proj_linear_layer(input)
q, k, v = proj_output.chunk(3, dim=-1)
q = q.reshape(bs, seqlen, num_head, head_dim).transpose(1, 2)
q = q.reshape(bs * num_head, seqlen, head_dim)
k = k.reshape(bs, seqlen, num_head, head_dim).transpose(1, 2)
k = k.reshape(bs * num_head, seqlen, head_dim)
v = v.reshape(bs, seqlen, num_head, head_dim).transpose(1, 2)
v = v.reshape(bs * num_head, seqlen, head_dim)
if additive_mask is None:
attn_prob = F.softmax(torch.bmm(q, k.transpose(-1, -2)) / math.sqrt(head_dim), dim=-1)
else:
additive_mask = additive_mask.tile((num_head, 1, 1))
attn_prob = F.softmax(torch.bmm(q, k.transpose(-1, -2)) / math.sqrt(head_dim) + additive_mask, dim=-1)
# output.shape = [bs * num_head, seqlen, head_dim]
output = torch.bmm(attn_prob, v)
output = output.reshape(bs, num_head, seqlen, head_dim).transpose(1, 2)
output = output.reshape(bs, seqlen, model_dim)
output = self.final_linear_layer(output)
return attn_prob, output
3.构建W_MHSA并计算复杂度
- 将patch组成的图片进一步划分成一个个更大的window
- 将三维的patch_embedding转换成图片格式
- 使用unfold将patch划分成window
- 在每个window内部计算MHSA
- window数目其实可以和
batch_size统一对待,因为window与window间没有交互计算 - 复杂度:假设窗的边长为W,计算每个窗的复度将$W^2$看成注意力机制中L
那么复杂度是$4W^2C^2+2W^4C$ - 假设patch的总数为L,那么窗的数目是$L/W^2$
- 所以总的复杂度是$4LC^2+2LW^2C$
- 不需要mask(每个窗内patch间有关联性
- window数目其实可以和
- 复杂度对比
- MHSA:$4LC^2+2L^2C$
- W-MHSA:$4LC^2+2LW^2C$
def window_multi_head_self_attention(patch_embedding, mhsa, window_size=4, num_head=2):
# 将4个patch组成一个window,一张图共4个window
num_patch_in_window = window_size * window_size
bs, num_patch, patch_depth = patch_embedding.shape
# 每一个patch中图片的h和w
# 将图片中每个patch看成一个像素点,在此基础上做window融合
# 假设有一个 256x256 大小的图像,我们将其划分为 16x16 大小的 patch。
# 每个维度上有 256/16=16 个 patch,所以总共有 16*16=256 个patch
# 将256个patch看成一张图片,那么图片的h,w就是16
image_h = image_w = int(math.sqrt(num_patch))
patch_embedding = patch_embedding.transpose(-1, -2)
patch = patch_embedding.reshape(bs, patch_depth, image_h, image_w)
# window.shape = [bs, num_window, window_depth]
window = F.unfold(patch, kernel_size=(window_size, window_size),
stride=(window_size,window_size)).transpose(-1, -2)
bs, num_window, patch_depth_times_num_patch_in_window = window.shape
# [bs * num_w, num_patch_in_window, patch_depth]
window = window.reshape(bs*num_window, patch_depth, num_patch_in_window).transpose(-1, -2)
# 送入注意力机制中的shape应该是[bs, len, dim]
# 而不同窗口间不需要计算注意力,所以bs*num_window, len=有多少个patch, dim=patch_depth
attn_prob, output = mhsa(window)
output = output.reshape(bs, num_window, num_patch_in_window, patch_depth)
return output
4.构建SW_MHSA
- 将上一步W_MHSA的结果转换成图片格式
- 假设已经做了新的window划分,这一步叫做shift-window
- 为了保持window数目不变从而有高效的计算,需要将图片的patch往左往上各自滑动半个窗口大小的步长,保持patch所属的window类别不变
- 将图片patch还原成window的数据格式
- [HTML_REMOVED]
- 由于cycle shift后,每个window形状规整,但存在不属于一个窗口的patch,所以需要生成mask
- 如何生成mask?
- 首先构建一个shift-window的patch所属的window类别矩阵
- 对该矩阵进行同样往左上各滑动半个窗口大小的操作
- 通过
unfold得到[bs, num_window, num_patch_in_window]形状的类别矩阵 - 扩维
[bs, num_window, num_patch_in_window, 1] - 将该矩阵与其转置矩阵做差,得到同类关系矩阵,(为0的位置上为同类,否则属于不同类
- 对同类关系矩阵中非零位置用负无穷填充,对于0位置用0填充,这样就构建好MHSA需要的mask了
- mask的shape是
[bs, num_window, num_patch_in_window, num_patch_in_window]
- 将window转换成三维,
[bs*num_window, num_patch_in_window, patch_depth] - 将三维格式特征和mask一同送入MHSA计算注意力
- 将注意力输出换成图片patch格式,
[bs, num_window, num_patch_in_window, patch_depth] - 为了恢复位置,将图片patch往右下滑动半个窗口大小
def window2image(msa_output):
bs, num_window, num_patch_in_window, patch_depth = msa_output.shape
window_size = int(math.sqrt(num_patch_in_window))
image_h = int(math.sqrt(num_window)) * window_size
image_w = image_h
# mas_output.shape = [bs, sqrt(num_window), sqrt(num_window), window_size, window_size]
# 而 image_h = sqrt(num_window) * window_size
msa_output = msa_output.reshape(bs, int(math.sqrt(num_window)), int(math.sqrt(num_window)),
window_size, window_size, patch_depth)
msa_output = msa_output.transpose(2, 3)
image = msa_output.reshape(bs, image_h*image_w, patch_depth)
image = image.transpose(-1, -2).reshape(bs, patch_depth, image_h, image_w)
return image
def shift_window(w_msa_output, window_size, shift_size, gernerate_mask=False):
bs, num_window, num_patch_in_window, patch_depth = w_msa_output.shape
# shape = [bs, depth, h, w]
w_msa_output = window2image(w_msa_output)
bs, patch_depth, image_h, image_w = w_msa_output.shape
rolled_w_msa_output = torch.roll(w_msa_output, shifts=(shift_size, shift_size),
dims=(2, 3))
shift_w_msa_input = rolled_w_msa_output.reshape(bs, patch_depth,
int(math.sqrt(num_window)),
window_size,
int(math.sqrt(num_window)),
window_size)
shift_w_msa_input = shift_w_msa_input.transpose(3, 4)
shift_w_msa_input = shift_w_msa_input.reshape(bs, patch_depth, num_window * num_patch_in_window)
shift_w_msa_input = shift_w_msa_input.transpose(-1, -2)
shifted_window = shift_w_msa_input.reshape(bs, num_window, num_patch_in_window, patch_depth)
if gernerate_mask:
additive_mask = build_mask_for_shifted_wmsa(bs, image_h, image_w, window_size)
else:
additive_mask = None
return shifted_window, additive_mask
def build_mask_for_shifted_wmsa(batch_size, image_h, image_w, window_size):
index_matrix = torch.zeros(image_h, image_w)
# 构造这个矩阵
# [1., 2., 2., 3.],
# [4., 5., 5., 6.],
# [4., 5., 5., 6.],
# [7., 8., 8., 9.]]
for i in range(image_h):
for j in range(image_w):
row_times = (i+window_size//2) // window_size
col_times = (j+window_size//2) // window_size
index_matrix[i, j] = row_times * (image_h // window_size) + row_times + col_times + 1
rolled_index_matrix = torch.roll(index_matrix, shifts=(-window_size//2, -window_size//2), dims=(0, 1))
rolled_index_matrix = rolled_index_matrix.unsqueeze(0).unsqueeze(0)
c = F.unfold(rolled_index_matrix, kernel_size=(window_size, window_size),
stride=(window_size, window_size)).transpose(-1, -2)
# 因为rolled_index_matrix的前两维是unsqueeze来的,大小都是1
# 所以这里的第三维,也就是原本的c*h*w=1*h*w=1*window_size*window_size=num_patch_in_window
c = torch.tile(c, [batch_size, 1, 1])
bs, num_window, num_patch_in_window = c.shape
# shape = [bs, num_window, num_patch_in_window, 1]
# 扩维为了广播
c1 = c.unsqueeze(-1)
# shape = [bs, num_window, num_patch_in_window, num_patch_in_window]
c2 = (c1 - c1.transpose(-1, -2)) == 0
valid_matrix = c2.to(torch.float32)
additive_mask = (1-valid_matrix) * -1e9
additive_mask = additive_mask.reshape(bs*num_window, num_patch_in_window, num_patch_in_window)
return additive_mask
def shift_window_multi_head_self_attention(w_msa_output, mhsa, window_size=4, num_head=2):
bs, num_window, num_patch_in_window, patch_depth = w_msa_output.shape
shifted_w_msa_input, additive_mask = shift_window(w_msa_output, window_size,
shift_size=-window_size//2, gernerate_mask=True)
shifted_w_msa_input = shifted_w_msa_input.reshape(bs * num_window, num_patch_in_window, patch_depth)
attn_prob, output = mhsa(shifted_w_msa_input, additive_mask)
output = output.reshape(bs, num_window, num_patch_in_window, patch_depth)
# 注意这里的shift_size是正的,与上面的相反,这样做是为了高效的计算window
output, _ = shift_window(output, window_size, shift_size=window_size//2, gernerate_mask=False)
return output
5.构建Patch Mergin
- 将window格式的特征转换成图片patch格式
- 利用unfold操作,按照
merge_size*merge_size的大小得到新patch,shape=[bs, num_patch_new, merge_size*merge_size*patch_depth_old] - 使用一个全连接对depth降维成0.5倍
- 输出的patch_embedding形状是
[bs, num_patch, patch_depth]
class PatchMerging(nn.Module):
def __init__(self, model_dim, merge_size, output_depth_scale=0.5):
super(PatchMerging, self).__init__()
self.merge_size = merge_size
self.proj_layer = nn.Linear(model_dim * merge_size * merge_size,
int(model_dim * merge_size * merge_size * output_depth_scale))
def forward(self, x):
bs, num_window, num_patch_in_window, patch_depth = x.shape
window_size = int(math.sqrt(num_patch_in_window))
# shape = [bs, patch_depth, image_h, image_w]
x = window2image(x)
merged_window = F.unfold(x, kernel_size=(self.merge_size, self.merge_size),
stride=(self.merge_size, self.merge_size)).transpose(-1, -2)
merged_window = self.proj_layer(merged_window)
return merged_window
6. 构建SwinTransformerBlock
- 包含LayerNorm, W-MHSA, MLP, SW-MHSA, 残差
- 输入是patch embedding
- 每个MLP有两层,分别是4*model_dim和model_dim大小
- 输出的是window的数据格式,
[bs, num_window, num_patch_in_window, patch_depth]
class SwinTransformerBlock(nn.Module):
def __init__(self, model_dim, window_size, num_head):
super(SwinTransformerBlock, self).__init__()
self.layer_norm1 = nn.LayerNorm(model_dim)
self.layer_norm2 = nn.LayerNorm(model_dim)
self.layer_norm3 = nn.LayerNorm(model_dim)
self.layer_norm4 = nn.LayerNorm(model_dim)
self.wsma_mlp1 = nn.Linear(model_dim, model_dim * 4)
self.wsma_mlp2 = nn.Linear(model_dim * 4, model_dim)
self.swsma_mlp1 = nn.Linear(model_dim, model_dim * 4)
self.swsma_mlp2 = nn.Linear(model_dim * 4, model_dim)
self.mhsa1 = MultiHeadSelfAttention(model_dim, num_head)
self.mhsa2 = MultiHeadSelfAttention(model_dim, num_head)
def forward(self, input):
bs, num_patch, patch_depth = input.shape
input1 = self.layer_norm1(input)
w_msa_output = window_multi_head_self_attention(input, self.mhsa1, window_size=4, num_head=2)
bs, num_window, num_patch_in_window, patch_depth = w_msa_output.shape
w_msa_output = input + w_msa_output.reshape(bs, num_patch, patch_depth)
output1 = self.wsma_mlp2(self.wsma_mlp1(self.layer_norm2(w_msa_output)))
output1 += w_msa_output
input2 = self.layer_norm3(input)
input2 = input2.reshape(bs, num_window, num_patch_in_window, patch_depth)
sw_msa_output = shift_window_multi_head_self_attention(input2, self.mhsa2, window_size=4, num_head=2)
sw_msa_output = output1 + sw_msa_output.reshape(bs, num_patch, patch_depth)
output2 = self.swsma_mlp2(self.swsma_mlp1(self.layer_norm4(sw_msa_output)))
output2 += sw_msa_output
output2 = output2.reshape(bs, num_window, num_patch_in_window, patch_depth)
return output2
7.构建Model
- 输入图片
- 先分块得到patch embedding
- 经过第一个stage
- 进行patch merging,在进行第二个stage
- 以此类推…
- 最后一个block的输出转换成patch embedding
[bs, num_patch, patch_depth] - 在时间维度平均池化,送入全连接得到输出
class SwinTransformerModel(nn.Module):
def __init__(self, input_image_channel=3, patch_size=4, model_dim_C=8, num_classes=10,
window_size=4, num_head=2, merge_size=2):
super(SwinTransformerModel, self).__init__()
patch_depth = patch_size * patch_size * input_image_channel
self.patch_size = patch_size
self.model_dim_C = model_dim_C
self.num_classes = num_classes
self.patch_embedding_weight = nn.Parameter(torch.randn(patch_depth, model_dim_C))
self.block1 = SwinTransformerBlock(model_dim_C, window_size, num_head)
self.block2 = SwinTransformerBlock(model_dim_C*2, window_size, num_head)
self.block3 = SwinTransformerBlock(model_dim_C*4, window_size, num_head)
self.block4 = SwinTransformerBlock(model_dim_C*8, window_size, num_head)
self.patch_mergin1 = PatchMerging(model_dim_C, merge_size)
self.patch_mergin2 = PatchMerging(model_dim_C*2, merge_size)
self.patch_mergin3 = PatchMerging(model_dim_C*4, merge_size)
self.final_layer = nn.Linear(model_dim_C * 8, num_classes)
def forward(self, image):
patch_embedding_naive = image2emb_naive(image, self.patch_size, self.patch_embedding_weight)
# block1
patch_embedding = patch_embedding_naive
print(patch_embedding.shape)
sw_msa_output = self.block1(patch_embedding)
print(f'block1_output {sw_msa_output.shape}')
merged_patch1 = self.patch_mergin1(sw_msa_output)
sw_msa_output_1 = self.block2(merged_patch1)
print(f'block2_output {sw_msa_output_1.shape}')
merged_patch2 = self.patch_mergin2(sw_msa_output_1)
sw_msa_output_2 = self.block3(merged_patch2)
print(f'block3_output {sw_msa_output_2.shape}')
merged_patch3 = self.patch_mergin3(sw_msa_output_2)
sw_msa_output_3 = self.block4(merged_patch3)
print(f'block4_output {sw_msa_output_3.shape}')
bs, num_window, num_patch_in_window, patch_depth = sw_msa_output_3.shape
sw_msa_output_3 = sw_msa_output_3.reshape(bs, -1, patch_depth)
pool_output = torch.mean(sw_msa_output_3, dim=1)
logits = self.final_layer(pool_output)
print(f'logits {logits.shape}')
return logits
8.测试代码
if __name__ == '__main__':
bs, ic, image_h, image_w = 4, 3, 256, 256
patch_size = 4
model_dim_C = 8
max_num_token = 16
num_classes = 10
window_size = 4
num_head = 2
merge_size = 2
patch_depth = patch_size * patch_size * ic
image = torch.randn(bs, ic, image_h, image_w)
model = SwinTransformerModel(ic, patch_size, model_dim_C, num_classes,
window_size, num_head, merge_size)
model(image)
9.运行结果
torch.Size([4, 4096, 8])
block1_output torch.Size([4, 256, 16, 8])
block2_output torch.Size([4, 64, 16, 16])
block3_output torch.Size([4, 16, 16, 32])
block4_output torch.Size([4, 4, 16, 64])
logits torch.Size([4, 10])
block output的含义是[bs, num_window, num_patch_in_window, patch_depth]
发现每次num_window都是减少了4倍,但是patch_depth只增加了2倍
