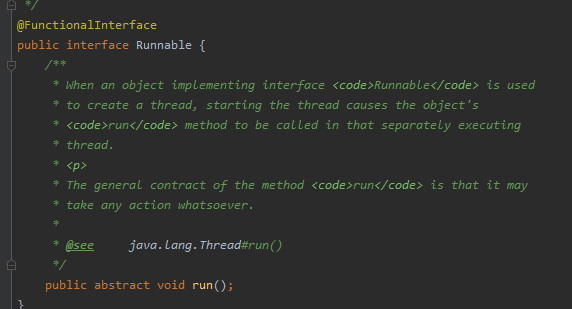
1、四大函数式接口
新时代的程序员: lambda表达式、链式编程、函数式接口、Stream流式计算
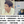
函数式接口:只有一个方法的接口
1.1、Function函数型接口
Function函数型接口,有一个输入参数,有一个输出参数,只要是 函数型接口 可以用 lambda表达式简化。

package main.java.com.syzd.function;
import java.util.function.Function;
public class FunctionDemo {
public static void main(String[] args) {
// Function function = new Function<String, String>() {
// @Override
// public String apply(String str) {
// System.out.println("function");
// return str;
// }
// };
//lambda表达式
Function<String, String> function = (str) -> {return str;};
System.out.println(function.apply("syzd"));
}
}
1.2、Predicate 断定型接口
package main.java.com.syzd.function;
import java.util.function.Predicate;
public class PredicateDemo {
public static void main(String[] args) {
// Predicate predicate = new Predicate<String>() {
// @Override
// public boolean test(String str) {
// return false;
// }
// };
Predicate<String> predicate = (str) -> { return true;};
System.out.println(predicate.test("A"));
}
}
1.3、Consumer 消费型接口
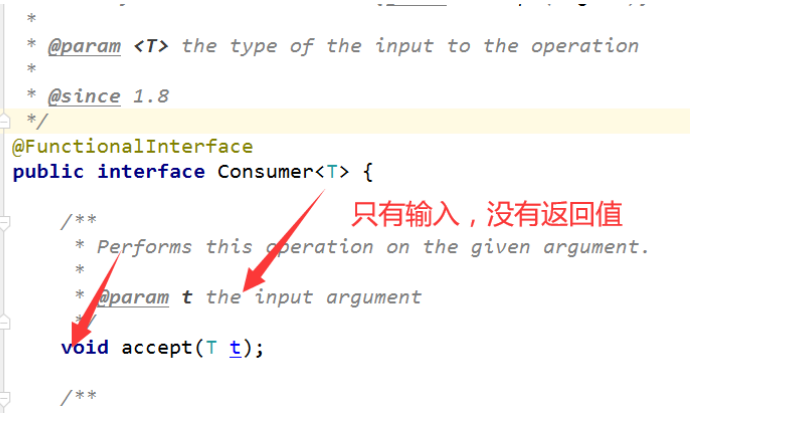
package main.java.com.syzd.function;
import java.util.function.Consumer;
public class ConsumerDemo {
public static void main(String[] args) {
// Consumer consumer = new Consumer<String>() {
// @Override
// public void accept(String str) {
// System.out.println("1111");
// }
// };
Consumer<String> consumer = (str) -> { System.out.println("1111");};
consumer.accept("A");
}
}
1.4、Suppier 供给型接口

package main.java.com.syzd.function;
import java.util.function.Supplier;
public class SuppierDemo {
public static void main(String[] args) {
// Supplier supplier = new Supplier<String>() {
// @Override
// public String get() {
// return "1";
// }
// };
Supplier<String> supplier = () -> { return "1";};
System.out.println(supplier.get());
}
}
2、Stream流式计算
什么是Stream流式计算
大数据:存储 + 计算
集合、Mysql本质都是存储东西的;
计算都应该交给流来操作!
package main.java.com.syzd.stream;
import java.util.Arrays;
import java.util.List;
/**
* Description:
* 题目要求: 用一行代码实现
* 1. Id 必须是偶数
* 2.年龄必须大于23
* 3. 用户名转为大写
* 4. 用户名倒序
* 5. 只能输出一个用户
**/
public class StreamDemo {
public static void main(String[] args) {
User u1 = new User(1, "a", 23);
User u2 = new User(2, "b", 23);
User u3 = new User(3, "c", 23);
User u4 = new User(6, "d", 24);
User u5 = new User(4, "e", 25);
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
list.stream()
.filter(u -> {return u.getId() % 2 == 0;})
.filter(u -> {return u.getAge() > 23;})
.map(u -> {return u.getName().toUpperCase();})
.sorted((uu1, uu2) -> {return uu2.compareTo(uu1);})
.limit(1)
.forEach(System.out::println);
}
}
3、ForkJoin
什么是 ForkJoin
ForkJoin 在JDK1.7中出现,并行执行任务!提高效率。在大数据量速率会更快!
大数据中: MapReduce 核心思想–>把大任务拆分为小任务!
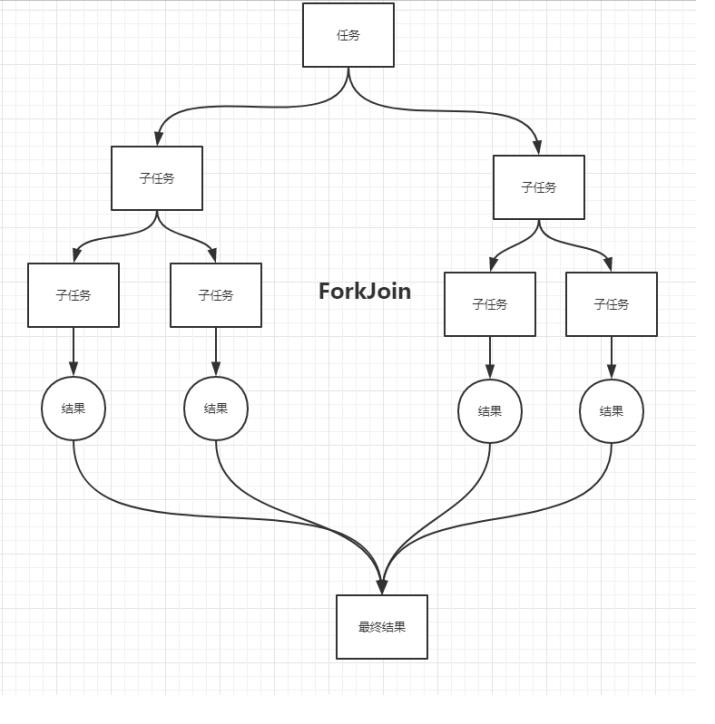
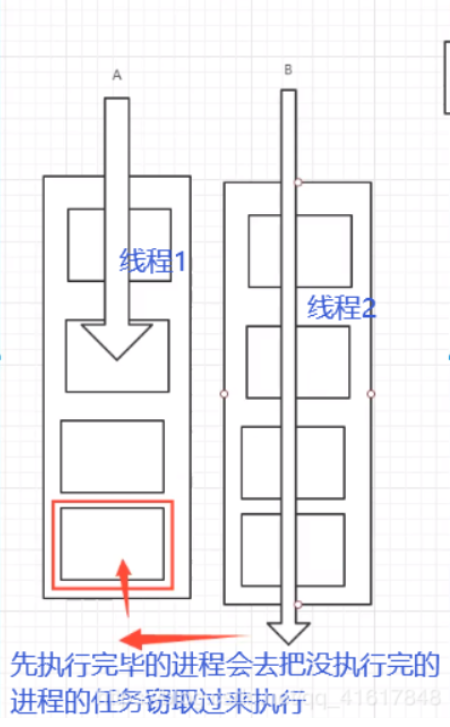
ForkJoin 特点:工作窃取
实现原理: 双端队列 从上面和下面都可以去拿到任务进行执行!
如何使用ForkJoin?
-
通过ForkJoinPool来执行
-
计算任务 execute(ForkJoinTask<?> task)
-
计算类要去继承 ForkJoinTask
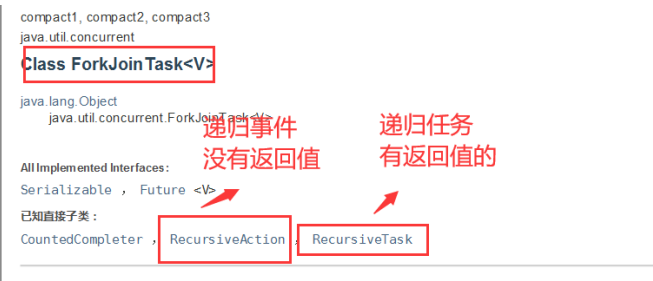
ForkJoin的计算案例
ForkJoin的计算类
package main.java.com.syzd.forkjoin;
import java.util.concurrent.RecursiveTask;
public class ForkJoinDemo extends RecursiveTask<Long> {
private long start;
private long end;
//临界值
private long temp = 10000L;
public ForkJoinDemo(long start, long end){
this.start = start;
this.end = end;
}
/**
* 计算方法
* @return
*/
@Override
protected Long compute() {
if ((end - start) < temp){
Long sum = 0L;
for (Long i = start; i < end; i++) {
sum += i;
}
return sum;
}else {
// 使用ForkJoin 分而治之 计算
// 1、计算平均值
long middle = (start + end) / 2;
// 拆分任务,把线程压入线程队列
ForkJoinDemo forkJoinDemo1 = new ForkJoinDemo(start, middle);
forkJoinDemo1.fork();
ForkJoinDemo forkJoinDemo2 = new ForkJoinDemo(middle, end);
forkJoinDemo2.fork();
long taskSum = forkJoinDemo1.join() + forkJoinDemo2.join();
return taskSum;
}
}
}
测试类
package main.java.com.syzd.forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.LongStream;
/**
* 同一个任务,别人效率高你几十倍!
*/
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//test1(); // 5598
//test2(); // 5315
//test3(); // 134
}
// 普通程序员
public static void test1(){
Long sum = 0L;
long start = System.currentTimeMillis();
for (Long i = 1L; i <= 10_0000_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
// 会使用ForkJoin
public static void test2() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinDemo(0L, 10_0000_0000L);
ForkJoinTask<Long> submit = forkJoinPool.submit(task);// 提交任务
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
public static void test3(){
long start = System.currentTimeMillis();
// Stream并行流 () (]
long sum = LongStream.rangeClosed(0L, 10_0000_0000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("sum="+"时间:"+(end-start));
}
}
.parallel().reduce(0, Long::sum)使用一个并行流去计算整个计算,提高效率。
4、异步回调
Future 设计的初衷: 对将来的某个事件的结果进行建模
但是我们平时都使用CompletableFuture
没有返回值的runAsync异步回调
package com.guocl.ff;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class FutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 发起 一个 请求
System.out.println(System.currentTimeMillis());
System.out.println("---------------------");
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
//发起一个异步任务
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+".....");
});
System.out.println(System.currentTimeMillis());
System.out.println("------------------------------");
//输出执行结果
System.out.println(future.get()); //获取执行结果
}
}
执行结果:
1666602291181
---------------------
1666602291275
------------------------------
ForkJoinPool.commonPool-worker-1.....
null
有返回值的supplyAsync异步回调
package com.guocl.ff;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class FutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// // 发起 一个 请求
// 成功的
// System.out.println(System.currentTimeMillis());
// System.out.println("---------------------");
// CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// //发起一个异步任务
// try {
// TimeUnit.SECONDS.sleep(2);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// System.out.println(Thread.currentThread().getName()+".....");
// });
// System.out.println(System.currentTimeMillis());
// System.out.println("------------------------------");
// //输出执行结果
// System.out.println(future.get()); //获取执行结果
//失败的
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync( () -> {
System.out.println(Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
int i=1/0;
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1024;
});
System.out.println(completableFuture.whenComplete((t, u) -> {
// success 回调
System.out.println("t=>" + t); //正常的返回结果
System.out.println("u=>" + u); //抛出异常的 错误信息
}).exceptionally((e) -> {
// error回调
System.out.println(e.getMessage());
return 404;
}).get());
}
}
失败时候的返回值:
ForkJoinPool.commonPool-worker-1
t=>null
u=>java.util.concurrent.CompletionException: java.lang.ArithmeticException: / by zero
java.lang.ArithmeticException: / by zero
404
成功时候的返回值:
ForkJoinPool.commonPool-worker-1
t=>1024
u=>null
1024
whenComplete: 有两个参数,一个是t 一个是u
T:是代表的 正常返回的结果;
U:是代表的 抛出异常的错误信息;
如果发生了异常,get可以获取到exceptionally返回的值;
5、JMM
5.1、对Volatile的理解
Volatile 是Java虚拟机提供 轻量级的同步机制
提到Volatile我们就会想到它的三个特点!
-
保证可见性
-
不保证原子性
-
禁止指令重排
如何实现可见性
volatile变量修饰的共享变量在进行写操作的时候会多出一行汇编:
0x01a3de1d:movb $0×0,0×1104800(%esi);0x01a3de24**:lock** addl $0×0,(%esp);
Lock前缀的指令在多核处理器下回引发两件事:
-
将当前处理器缓存行的数据写回到系统内存。
-
这个写回内存的操作会使其他CPU里缓存了该内存地址的数据无效。
多处理器总线嗅探:
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存后再进行操作,但操作不知道何时会写回到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是在 多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议, 每个处理器通过嗅探在总线上传播的数据来检查自己的缓存是不是过期了,如果处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读取到处理器缓存中。
5.2、什么是JMM
JMM : Java内存模型,不存在的东西,概念!约定!
关于JMM的一些同步的约定:
-
线程解锁前,必须把共享变量立刻刷回主存。
-
线程加锁前,必须读取主存中的最新值到工作内存中!
-
加锁和解锁是同一把锁
线程中分为 工作内存、主内存。
8种操作
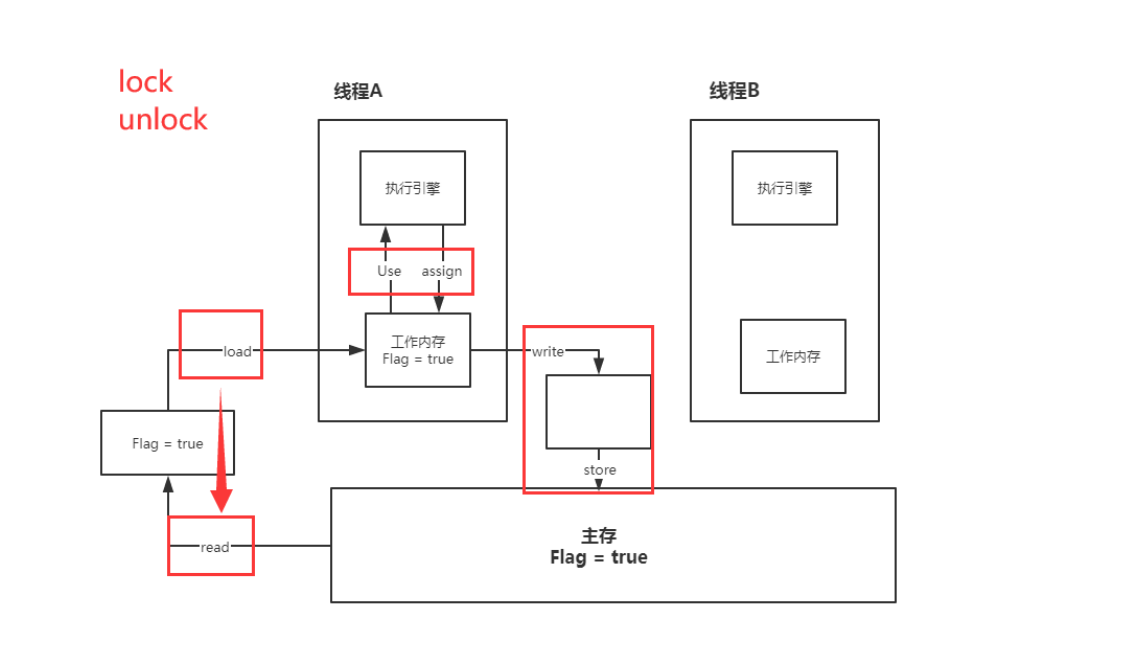
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类
型的变量来说,load、store、read和write操作在某些平台上允许例外)
-
Read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用;
-
load(载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中;
-
Use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令;
-
assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中;
-
store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用;
-
write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中;
-
lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态;
-
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定;
JMM对这八种指令的使用,制定了如下规则:
-
不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须
write -
不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
-
不允许一个线程将没有assign的数据从工作内存同步回主内存
-
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量
实施use、store操作之前,必须经过assign和load操作 -
一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解
锁 -
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,
必须重新load或assign操作初始化变量的值 -
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
对一个变量进行unlock操作之前,必须把此变量同步回主内存
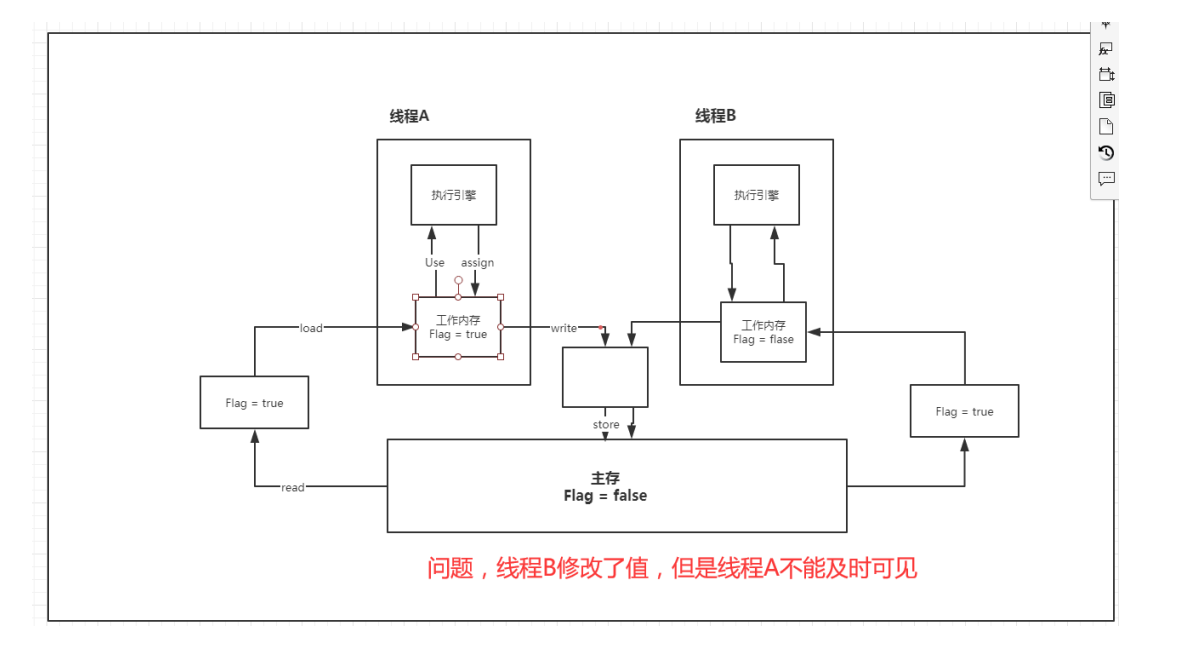
问题: 程序不知道主内存的值已经被修改过了
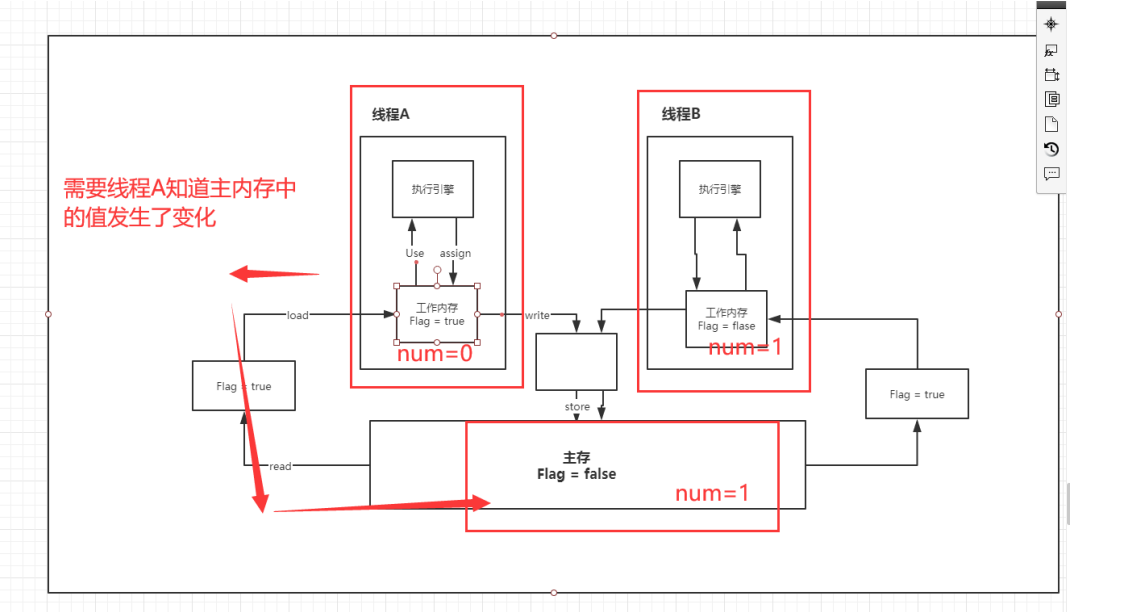
6、volatile
6.1、保证可见性
package main.java.com.syzd.tvolatile;
import java.util.concurrent.TimeUnit;
public class JMMDemo {
// 不加 volatile 程序就会死循环!
// 加 volatile 可以保证可见性
private volatile static int num = 0;
public static void main(String[] args) { // main
new Thread(()->{ // 线程 1 对主内存的变化不知道的
while (num==0){
}
}).start();
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
num = 1;
System.out.println(num);
}
}
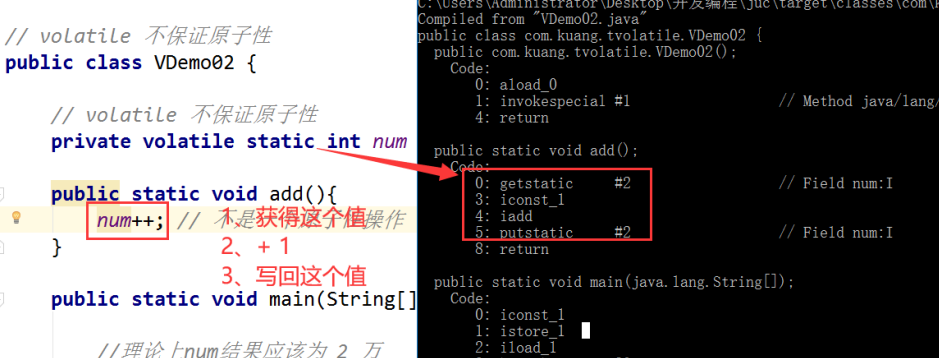
6.2、不保证原子性
原子性 : 不可分割
线程A在执行任务的时候,不能被打扰的,也不能被分割。要么同时成功,要么同时失败。
package main.java.com.syzd.tvolatile;
// volatile 不保证原子性
public class VDemo02 {
// volatile 不保证原子性
private volatile static int num = 0;
public static void add(){
num++;
}
public static void main(String[] args) {
//理论上num结果应该为 2 万
for (int i = 1; i <= 20; i++) {
new Thread(()->{
for (int j = 0; j < 1000 ; j++) {
add();
}
}).start();
}
while (Thread.activeCount()>2){ // main gc
//当线程数小于等于2的时候就停止,因为有两个默认线程:mian、GC
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " " + num);
}
}
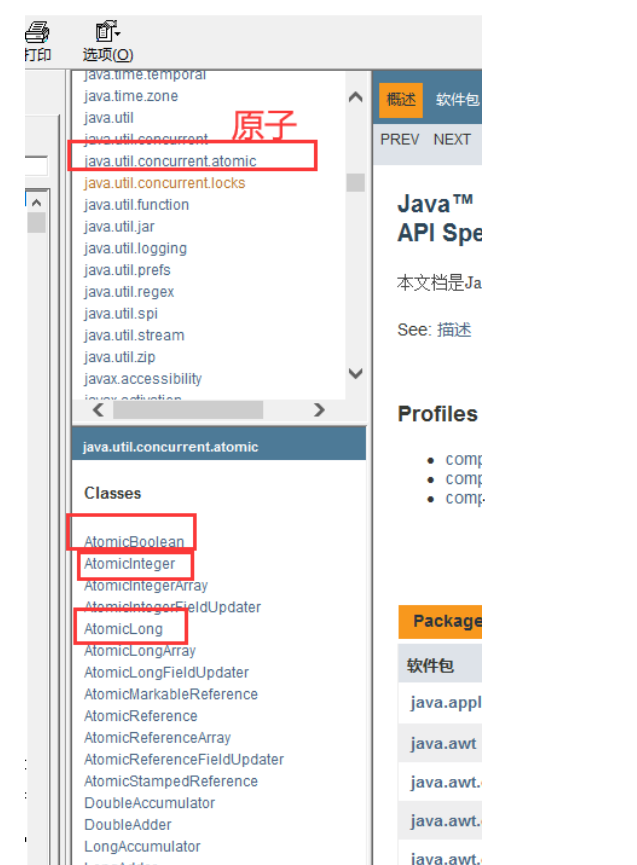
>如果不加 lock 和 synchronized ,怎么样保证原子性?
使用原子类,解决 原子性问题
package main.java.com.syzd.tvolatile;
import java.util.concurrent.atomic.AtomicInteger;
// volatile 不保证原子性
public class VDemo02 {
// volatile 不保证原子性
private volatile static AtomicInteger num = new AtomicInteger();
public static void add(){
// num++; // 不是一个原子性操作
num.getAndIncrement(); // AtomicInteger + 1 方法, CAS
}
public static void main(String[] args) {
//理论上num结果应该为 2 万
for (int i = 1; i <= 20; i++) {
new Thread(()->{
for (int j = 0; j < 1000 ; j++) {
add();
}
}).start();
}
while (Thread.activeCount()>2){ // main gc
//当线程数小于等于2的时候就停止,因为有两个默认线程:mian、GC
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " " + num);
}
}
这些类的底层都直接和操作系统挂钩!在内存中修改值!Unsafe类是一个很特殊的存在!
6.3、指令重排
什么是 指令重排:你写的程序,计算机并不是按照你写的那样去执行的。
源代码–>编译器优化的重排–> 指令并行也可能会重排–> 内存系统也会重排—> 执行
处理器在进行指令重排的时候,考虑:数据之间的依赖性!
int x = 1; // 1
int y = 2; // 2
x = x + 5; // 3
y = x * x; // 4
我们所期望的:1234 但是可能执行的时候回变成 2134 1324
可不可能是 4123!

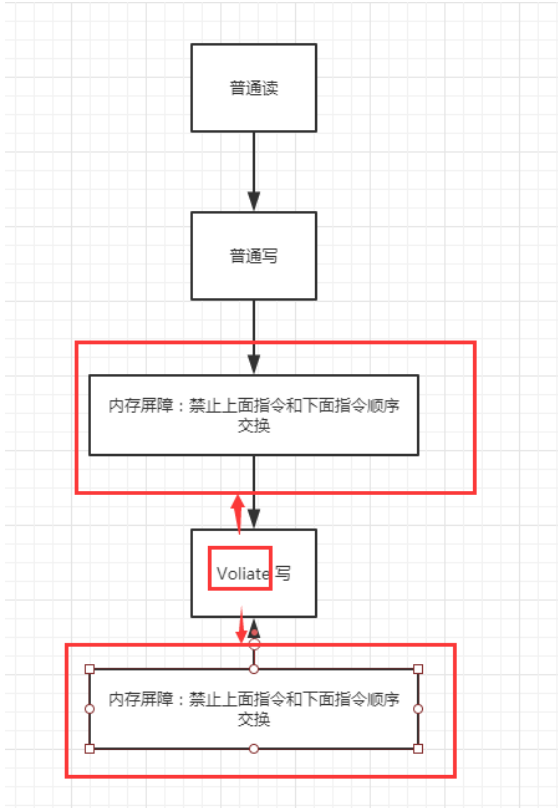
volatile可以避免指令重排:
Volatile中会加一道内存的屏障,这个内存屏障可以保证在这个屏障中的指令顺序。
内存屏障:CPU指令。
- 作用:
- 保证特定的操作的执行顺序;
- 可以保证某些变量的内存可见性(利用这些特性,就可以保证volatile实现的可见性)
总结:
Volatile 是可以保持 可见性。不能保证原子性,由于内存屏障,可以保证避免指令重排的现象产生!
面试官:那么你知道在哪里用这个内存屏障用得最多呢?单例模式
