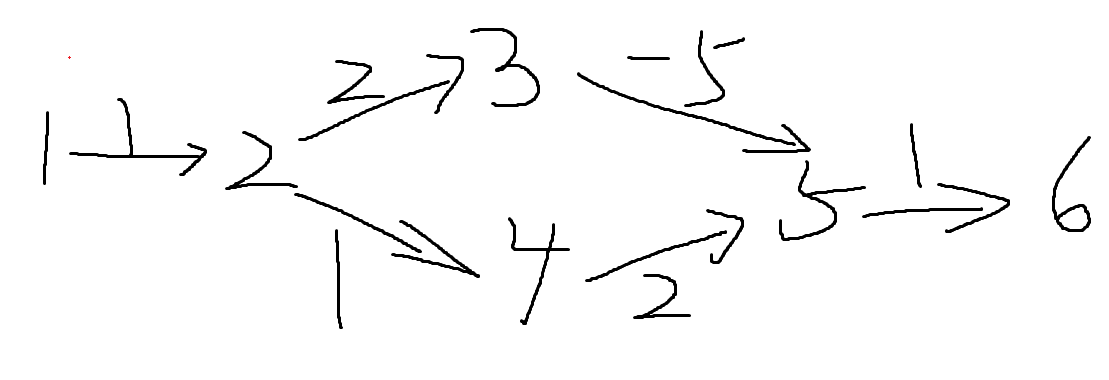//spfa,可以进行负权值路径判断,是bellman_fold的优化
#include<iostream>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int N = 1e5 + 10;
int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N];
void add(int a, int b, int c){
e[idx] = b;
w[idx] = c;
ne[idx] = h[a];
h[a] = idx ++;
}
int spfa(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true; //该点在队列中,防止存储重复的点(可以看做是自定义为true在队列中,false不在队列中而写的一行代码)
while (q.size()){
int t = q.front();
q.pop();
st[t] = false; //点从队列里出来,就更新为false表示不在队列了*****
for (int i = h[t]; i != -1; i = ne[i]){
int j = e[i];
//比较bellman_fold算法的优化就是这里的松弛操作针对权值的变小,而不是全部遍历
if (dist[j] > dist[t] + w[i]){ /*这一步的原因是因为如果该点导致到j点的路径变小,则可能影响后面的值,
如果该点不对dist[j]产生影响,则该条路径可能不产生影响,即去寻找能够产生路径变短的点作为下一次队列的头
进行路径的下一次遍历,在去进行判断(一步一步的走)*/
dist[j] = dist[t] + w[i];
if (!st[j]){ //如果不在队列里就加入队列里*****
/*st[j]是当前t的后一个连接到的元素如果没有被遍历过就进入队列,
下一次就以该元素为头继续进行邻接表的遍历,
然后再进行松弛操作,由于有这一点的操作,所以不会略过有负权值边的情况,因为都会被遍历到*/
st[j] = true; //如果在队列里就记为true*****
q.push(j);
}
}
}
}
return dist[n];
}
int main(){
cin >> n >> m;
memset(h, -1, sizeof h);
for (int i = 0; i < m; i ++){
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
int t = spfa();
if (t == 0x3f3f3f3f) puts("impossible");
else cout << t << endl;
return 0;
}
dijkstra不能做的事