
要比赛了,整理一下重要考点。
为了美观加了 MarkDown
进制转换
- $N$ 进制转十进制
十进制转N进制的方法是“除N取余,逆序排列”,就是用N除去要进行转换的十进制数,得到一个商和余数,再用N除以商得到又一个商和余数,一直继续下去,直到商为0,将得到的所有余数逆序排列,得到的就是N进制数了。
例:将十进制数37转为二进制,计算过程如下:
将余数逆序排列,得到二进制结果100101。
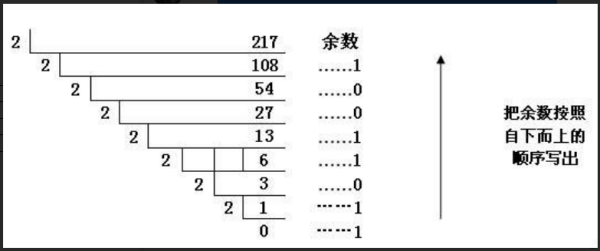
- 十进制转 $N$ 进制
N进制转十进制的方法是:按权相加法。即把N进制数先写成加权系数展开式,然后再按十进制的加法规则求和,得到对应十进制数。
例:将八进制数转为十进制,计算过程如下:
(3567)8=(3*8*8*8+5*8*8+6*8+7)10
=(512+320+48+7)10
=(887)10
栈
栈是数据结构中一种常用的结构。可以想象成一个没有盖的圆桶。只有两个操作:**入栈和出栈**。
概念:入栈、出栈、栈顶。入栈和出栈都是针对栈顶元素操作的。
二叉树
二叉树(Binary tree)是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。二叉树特点是每个节点最多只能有两棵子树,且有左右之分。
二叉树是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个节点。
哈夫曼树和哈夫曼编码
一、如何构造一棵哈夫曼树?(哈夫曼树也是一棵二叉树)
给n个点,每个点都有权值,构造一棵哈夫曼树。每次选剩下的两棵根权值最小的树合并成一棵新树,新树的根权值等于两棵合并前树的根权值和。(一开始一个点也看成一棵树,只不过这棵树没有孩子节点)
二、基本概念
树的路径长度PL:从树根到树的每个节点的路径长度(每条边长度为1)之和(完全二叉树为这种路径长度最短的二叉树)。
树的带权路径长度WPL:树的所有叶子节点的带权路径长度(该节点到根节点路径长度与节点上权的乘积)之和。
透彻理解树的路径长度和树的带权路径长度这两个概念非常重要。
哈夫曼树:带权路径长度WPL最短的二叉树(最优二叉树)构造这种树的算法最早是由哈夫曼(Huffman)1952年提出,这种树在信息检索中很有用。
三、哈夫曼编码
一篇电文,原文为:AMCADEDDMCCAD。现在要把原文转换成01串发送给对方。为了节省资源,我们当然希望翻译好的01串长度尽量的短。怎么办?
研究发现:1、只有5个字母E,M,C,A,D; 2、这5个字母的使用频度分别为{E,M,C,A,D}= {1,2,3,3,4}。
用频度为权值生成哈夫曼树,并在叶子上标注对应的字母,在树枝上标注分配码“0”或“1”
排序
排序稳定性
排序算法常考的一个知识点就是该算法是否稳定,所以排序算法分为稳定排序和非稳定排序。什么是排序的稳定性呢?假定一个数列排序前有两个数(或两个以上)相等,经过某种排序方法后,仍能保持它们在排序之前的相对次序(相对前后关系),我们就说这种排序方法是稳定的。反之,就是非稳定的。比如:一组数排序前是a1,a2,a3,a4,a5,其中a2=a4,经过某种排序后为a1,a2,a4,a3,a5,则我们说这种排序是稳定的,因为排序后a2还是在a4的前面。假如变成a1,a4,a2,a3,a5就不是稳定的了。注意:能保证任何数列排序后都稳定的排序算法才是稳定的,否则为非稳定(有些非稳定排序算法排序后的数列有可能呈现稳定状态)
内排序和外排序
在排序过程中,所有需要排序的数都在内存,并在内存中调整它们的存储顺序,称为内排序;在排序过程中,只有部分数被调入内存,并借助内存调整数在外存中的存放顺序排序方法称为外排序。
一、冒泡排序
for i:=1 to (n-1) do
for j:=n-1 downto i do
if a[j+1]>a[j] then //如果是降序,则a[j+1]<a[j]
begin
tmp:=a[j];
a[j]:=a[j+1];
a[j+1]:=tmp;
end;
二、选择排序
[算法描述]第一趟扫描所有数据,选择其中最小的一个与第一个数据互换;第二趟从第二个数据开始向后扫描,选择最小的与第二个数据互换;依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程.
初始关键字[49 38 65 97 76 13 27 49]
第一趟排序后 13[38 65 97 76 49 27 49]
第二趟排序后 13 27[65 97 76 49 38 49]
第三趟排序后 13 27 38[97 76 49 65 49]
第四趟排序后 13 27 38 49[49 97 65 76]
第五趟排序后 13 27 38 49 49[97 97 76]
第六趟排序后 13 27 38 49 49 76[76 97]
第七趟排序后 13 27 38 49 49 76 76[97]
最后排序结果 13 27 38 49 49 76 76 97
方案一:
for i:=1 to (n-1) do
begin
k:=i;
for j:=(i+1) to n do
if a[j]<a[k] then k:=j; //降序:a[j]>a[k]
x:=a[i];
a[i]:=a[k];
a[k]:=x;
end;
方案二:
for i:=1 to (n-1) do
for j:=(i+1) to n do
if a[i]>a[j] then //降序:a[i]<a[j]
begin
k:=a[i];
a[i]:=a[j];
a[j]:=k;
end;
三、插入排序
[算法描述]当前a[1]..a[i-1]已排好序了,现要插入a[i]到a[1]..a[i-1]之间的某个位置,使a[1]..a[i]有序。
for i:=2 to n do
begin
x:=a[i];
j:=i-1;
while x<a[j] do
begin
a[j+1]:=a[j];
j:=j-1;
end;
a[j+1]:=x;
end;
四、快速排序
[算法描述] 这个算法一年至少打365次,所以要背且不许出一点点错。设有一无序数组a有n个元素.
①以数组a的中点元素为参考值;
②将中点左边大于(或小于)参考值的与中点右边小于(或大于)参考值的元素互换位置;
③对中点左边的元素执行快排操作;
④对中点右边的元素执行快排操作。
procedure qsort(l,r:longint);
var i,j,t,x:longint;
begin
i:=l; j:=r;
x:=a[(i+j)div 2];//其实用a[random(j-i+1)+i]更快
repeat
while (a[i] < x) do inc(i); //降序:a[i]>x
while (x < a[j]) do dec(j); //降序:x>a[j]
if (i<=j) then //除了这里含有等号,其他地方都没有的
begin
t:=a[i]; a[i]:=a[j]; a[j]:=t;
//如果是为记录数组排序的话,t必须是记录类型的
inc(i); dec(j); //缺了这里,就会死循环
end;
until (i>j);
if (l<j) then qsort(a,l,j);
if (i<r) then qsort(a,i,r);
end;
五、堆排序
procedure heap(n,k:longint); {向下调整}
var x,i,j:longint;
begin
i:=k;
x:=a[k];
j:=2*k;
while j<=n do
begin
if (j<n) and (a[j]<a[j+1]) then j:=j+1; {小根堆:(j<n) and (a[j]>a[j+1])}
if x<a[j] then begin a[i]:=a[j]; i:=j; j:=j*2; end {小根堆:x>a[j]}
else j:=n+1;
end;
a[i]:=x;
end;
procedure heapsort(n:integer); {堆排序}
Var i:longint;
begin
for i:=n div 2 downto 1 do heap(n,i);{建立初始堆,且产生最大值a[1]}
{下面每次输出堆顶—最大值a[1],然后最后一个a[n]放a[1],dec(n),再调整a[1]的值的位置}
while(n>0)do
begin
writeln(a[1]); a[1]:=a[n]; dec(n);
heap(n,1);
end;
end;
六、归并排序
[源程序]
{a为序列表,tmp为辅助数组}
procedure merge(var a:arr; l,mid,r:integer);
{将已排序好的子序列a[l..mid]与a[mid+1..r]合并为有序的tmp[l..r]}
var i,j,t:integer;
tmp:arr;
begin
t:=l;i:=l;j:=mid+1;{t为tmp指针,I,j分别为左右子序列的指针}
while (i<=mid)and(j<=r) do begin
if (a[i]<=a[j])) then begin
tmp[t]:=a[i]; inc(i);
end
else begin
tmp[t]:=a[j]; inc(j);
end;
inc(t);
end;
if i<=mid then begin
for k:=i to mid do begin
tmp[t]:=a[k]; inc(t);
end;
end
else if j<=r then
begin
for k:=j to r do begin
tmp[t]:=a[k];inc(t);
end;
end;
for i:=l to r do a[i]:=tmp[i];
end;{merge}
procedure merge_sort(var a:arr;l,r: integer); {合并排序a[p..r]}
var mid:integer;
begin
if l<>r then begin
mid:=(l+r) div 2;
merge_sort (a,l,mid);
merge_sort (a,mid+1,r);
merge (a,l,mid,r);
end;
end;
{main}
begin
merge_sort(a,1,n);
end.
hash表和二叉搜索树
求最小生成树的Kruskal算法
求最小生成树的Kruskal算法
最小生成树算法的目标:一个n个点的图,选若干条边(一定是n-1条)使得图连在一起,并且所有选中的边的长度和最小。
求最小生成树的prim算法
给出一个n个点的连通图,首先选中一个点(一般为第一个点),每次选和已选中的所有点相连的边中最小一条(该边两个端点必须一个是已选中点,另外一个为还没选的点)。
原码、补码、反码
原码、反码、补码的基本概念
字节:8各位。
字长:若干个字节。到底是几个字节?具体看是哪种CPU。比如2010普及组第11题就假设一个字长只有一个字节8个位。
下来原码、反码,补码都是建立在机器数在一个字长上的表示。为了方便理解,我们假设字长为一个字节。读者要注意事实上为32位CPU字长为4个字节,64位CPU字长为8个字节。
原码:首位为符号位,其余为真值。
原码总结: 特点:简单。
范围:比如字长为8位,则范围为 11111111(-255) 至 01111111(+255)。
缺点:0有两个表示,分别为正零(00000000)和负零(10000000),给计算机计算带来不便。
反码:首位为符号位,其它位分正数和负数两种情况。
反码正数:所有位和原码一样;
反码负数:除了符号位和原码一样,其他位相反。
比如:77的反码表示为01001101;
-77的反码表示为10110010。
补码总结:同样0有两个表示,也没有原码简单,补码存在的意义就是为了连接原码和补码。下来让我们看看补码是怎样的。
补码:分正数和负数两种情况。
补码正数:所有位和反码一样,当然也和原码一样。所以正数是:原码、反码、补码的表示都一样。
补码负数:等于反码加1。简单的一句话,其实很麻烦。
比如:77的补码表示为01001101(和原码、反码一致);
-77的补码表示为10110011。
加1之后会有进位,因为补码没有符号位,所以负零的补码表示也是00000000。
补码总结:
特点:表示比补码更麻烦。但是解决了一个问题:0只有一种表示。
原码 反码 补码
正零 00000000 00000000 00000000
负零 10000000 11111111 00000000
OI常识
一:NOI官方网站:http://www.noi.cn/
获奖信息和比赛注意实现一般都在这个网站公布。
二:关于NOI系列赛编程语言使用限制的规定:http://www.noi.cn/about/rules/362-noi
注意:
1、C和C中64位整数只能使用long long类型及unsigned long long类型。
2、C可以使用STL中的模板。
3、PASCAL程序中禁止使用除system库(自动加载)和math库(须用uses math子句)之外的其他单元。
三:NOI系列活动的主办方:中国计算机学会。
四:组织机构
NOI科学委员会:http://www.noi.cn/about/organization/50-noi
NOI竞赛委员会:http://www.noi.cn/about/organization/51-noi
rp++
《java》
6
# 您的模板代码是$JAVA$是在搞笑吗?
# 。 。 。
Markdown中的
C++语法错误了吧管他呢,看得懂就行哈# 。。。
# $\Huge\color{eee}{。。。}$
我要气死你们,等CSP结束之后再来发
(龟速逃我****
我直接变成电报员