
$\color{blue}{\texttt{C++}}$$\color{orange}{数据结构}\color{}{基础篇目录}$
$\ \ $
$$第三章 \ \ \ \ 链表$$
$\ \ \ $
链表呢……太常见了,简直可以说是随处可见
我简单介绍一下
链表支持在任意位置插入或删除,但只能按顺序依次访问其中的元素。我们可以用一个 $struct$(结构体)表示链表的节点,其中可以储存任意数据。另外用 $prev$ 和 $next$ 两个指针指向前后相邻的两个节点,构成一个常见的双向链表结构。为了避免在左右两端或者空链表中访问越界,我们通常建立额外的两个节点 $head$ 与 $tail$ 代表链表头尾
大家大概看一下……
关于链表我不多说了,接下来写一种常用的实现链表的参考程序(来自《算法竞赛进阶指南》)
struct Node{
int value;
Node *prev,*next;
};
Node *head, *tail;
void initialize(){ //新建链表
head = new Node();
tail = new Node();
head -> next = tail;
tail -> prev = head;
}
void insert(Node *p, int val){ //在p后插入包含数据val的新节点
q = new Node();
q -> value = val;
p -> next -> prev = q;
q -> next = p -> next ;
p -> next = q;
q -> prev = p;
}
void remove(Node *p){ //删除p
p -> prev -> next = p -> next;
p -> next -> prev = p -> prev;
delete p;
}
void recycle(){ //链表内存回收
while(head != tail){
head = head -> next;
delete head -> prev;
}
delete tail;
}
建议大家把上面链接的四道题做一下,知道链接在哪吧?
我就不高兴讲了
邻接表
邻接表是树和图的一般储存方式,也是一个需要掌握的结构
那啥是邻接表呢?
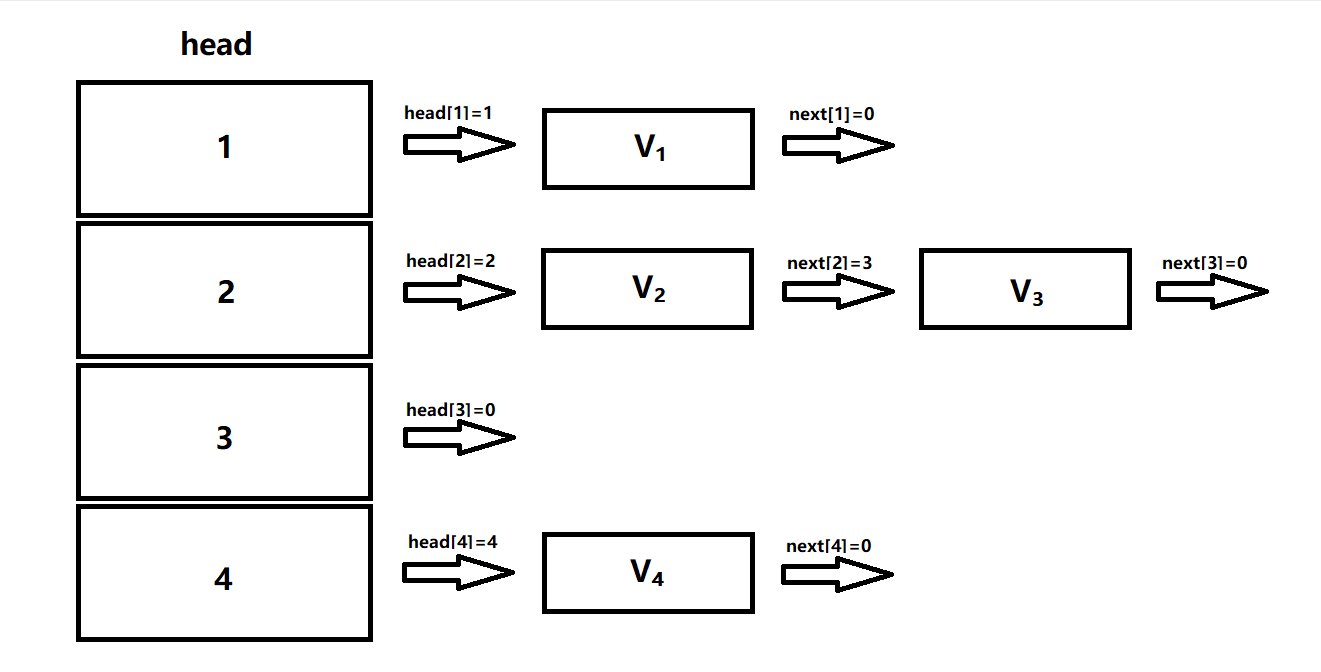
看图,邻接表就相当于“带有索引数组的多个数据结构”
可以看待每一类有个代表元素“表头”,所有的表头就构成了一个表头数组head
如上图,一共有4个数据节点 $V_1~V_4$ ,它们被分成了三类,通过head可以定位到每一类所构成的链表进行遍历
当需要插入新节点的时候,我们可以通过head对应到新节点所属的链表表头,将数据在表头插入
还是上图,用数组模拟了链表实现,,head与next中保存了数组v的下标,相当于指针,0就指向空,v存储每条边的终点
//初始化
int head[N],next[N],v[N],edge[N],size=0; //注:如果用万能头文件数组名则不能用next,可用nxt替代
//加入有向边(x,y),值为z
void add(int x,int y,int z){
v[++size] = y;
edge[size] = z;
next[size] = head[x];
head[x] = size;
}
//访问从x出发的所有边
for(int i=head[x];i;i=next[i]){
int y = v[i];
int z = edge[i];
}
上面的代码用数组模拟链表储存了一张带权有向图的邻接表结构
至于无向图,可以看作两条有向边插入

前排支持
Orz