
题目描述
有 n 座城市,编号从 1 到 n。编号为 x 和 y 的两座城市直接连通的前提是:x 和 y 的公因数中,至少有一个 严格大于 某个阈值 threshold。更正式地说,如果存在整数 z,且满足以下所有条件,则编号 x 和 y 的城市之间有一条道路:
x % z == 0y % z == 0z > threshold
给定两个整数 n 和 threshold,以及一个待查询数组,请你判断每个查询 queries[i] = [a_i, b_i] 指向的城市 a_i 和 b_i 是否连通(即,它们之间是否存在一条路径)。
返回数组 answer,其中 answer.length == queries.length。如果第 i 个查询中指向的城市 a_i 和 b_i 连通,则 answer[i] 为 true;如果不连通,则 answer[i] 为 false。
样例
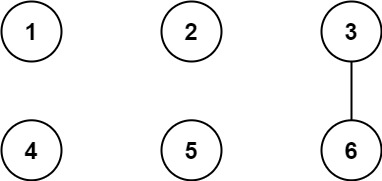
输入:n = 6, threshold = 2, queries = [[1,4],[2,5],[3,6]]
输出:[false,false,true]
解释:每个数的因数如下:
1: 1
2: 1, 2
3: 1, 3
4: 1, 2, 4
5: 1, 5
6: 1, 2, 3, 6
所有大于阈值的的因数已经加粗标识,只有城市 3 和 6 共享公约数 3,因此结果是:
[1,4] 1 与 4 不连通
[2,5] 2 与 5 不连通
[3,6] 3 与 6 连通,存在路径 3--6
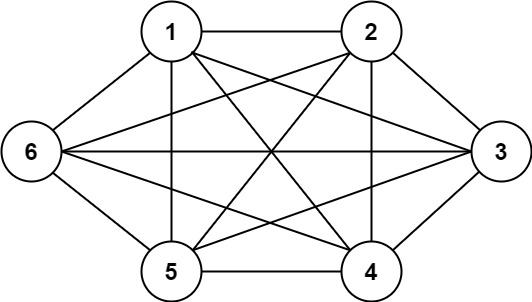
输入:n = 6, threshold = 0, queries = [[4,5],[3,4],[3,2],[2,6],[1,3]]
输出:[true,true,true,true,true]
解释:每个数的因数与上一个例子相同。
但是,由于阈值为 0,所有的因数都大于阈值。
因为所有的数字共享公因数 1,所以所有的城市都互相连通。
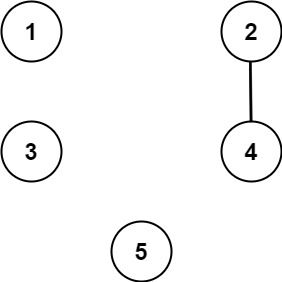
输入:n = 5, threshold = 1, queries = [[4,5],[4,5],[3,2],[2,3],[3,4]]
输出:[false,false,false,false,false]
解释:只有城市 2 和 4 共享的公约数 2 严格大于阈值 1,所以只有这两座城市是连通的。
注意,同一对节点 [x, y] 可以有多个查询,并且查询 [x,y] 等同于查询 [y,x]。
限制
2 <= n <= 10^40 <= threshold <= n1 <= queries.length <= 10^5queries[i].length == 21 <= a_i, b_i <= citiesa_i != b_i
算法
(素数筛,并查集) $O(n \log \log n + Q)$
- 通过古典的筛素数的方式发现连通关系,即从
i = threshold + 1开始,如果 $i$ 没有被筛过,则将2 * i, 3 * i, ...的数组都标记被筛过,且通过并查集合并(i, 2 * i), (i, 3 * i)。 - 每一轮中被筛掉的数字,都会在同一个连通块中。
- 查询时直接查询并查集。
时间复杂度
- 普通筛法的时间复杂度为 $O(n \log \log n)$。
- 假设并查集单次操作的时间复杂度为常数,总时间复杂度为 $O(n \log \log n + Q)$。
空间复杂度
- 需要 $O(n)$ 的额外空间存储筛法和并查集的数据结构。
C++ 代码
class Solution {
private:
vector<int> f, sz;
int find(int x) {
return x == f[x] ? x : f[x] = find(f[x]);
}
void merge(int x, int y) {
int fx = find(x), fy = find(y);
if (fx == fy)
return;
if (sz[fx] < sz[fy]) {
f[fx] = fy;
sz[fy] += sz[fx];
} else {
f[fy] = fx;
sz[fx] += sz[fy];
}
}
public:
vector<bool> areConnected(int n, int threshold, vector<vector<int>>& queries) {
f.resize(n + 1);
sz.resize(n + 1);
for (int i = 1; i <= n; i++) {
f[i] = i;
sz[i] = 1;
}
vector<bool> isFiltered(n + 1, false);
for (int i = threshold + 1; i <= n; i++) {
if (isFiltered[i])
continue;
for (int j = i + i; j <= n; j += i) {
merge(i, j);
isFiltered[j] = true;
}
}
vector<bool> ans;
for (const auto &q : queries)
ans.push_back(find(q[0]) == find(q[1]));
return ans;
}
};

这里的sz数组有用到吗?
查了《算法竞赛进阶指南》,原来是按秩合并~
路径压缩+按秩合并可以保证不爆栈
为什么进阶指南上说一般用路径压缩就足够了?y总也说路径压缩用起来实际上几乎是O(1)时间的
爆栈是指函数调用太深出现的吗~
如果栈空间充足,是不需要再按 size 合并的。如果只路径压缩,可能出现单次查询的递归达到 $O(n)$。