
思路
因为每个单词的长度是固定的为
w,单词数量为m,所以我们可以用一个长度固定为w * m的一个滑动窗口去做这道题每次枚举一个字母的长度
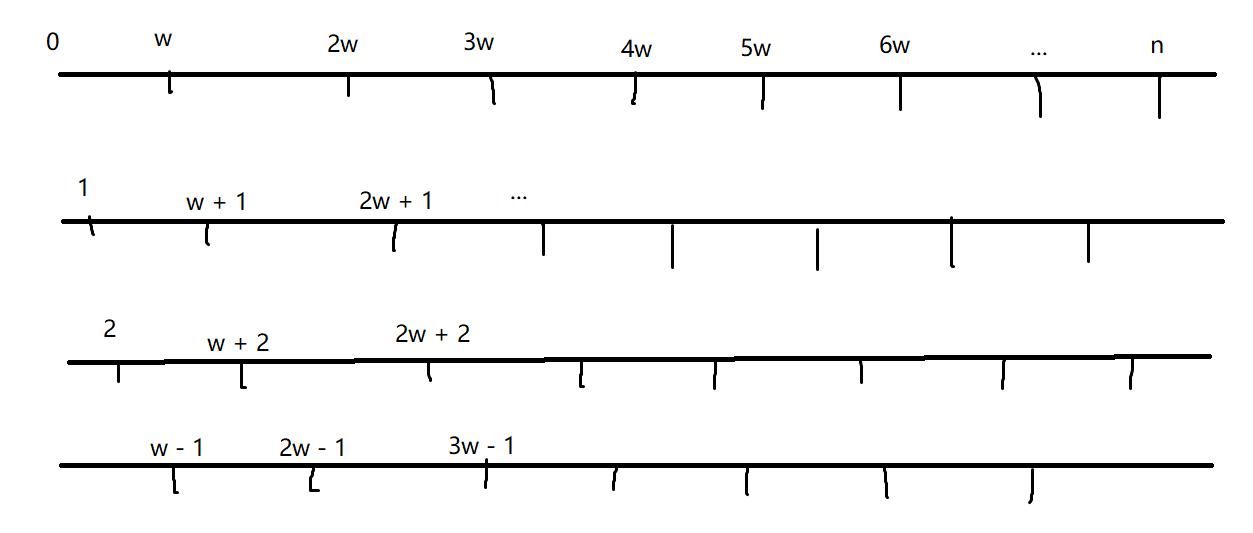
我们开两个哈希表一个哈希表存储的是words中每个单词的数量即
tot另一个存储每次枚举的时候滑动窗口中的每个单词的数量,然后每次用一个变量
cnt去存储wd滑动窗口中的有效单词数,如果cnt == m则在res中加入这个滑动窗口的开始位置这个时候有两种方法(下面那一种, 还有字符串哈希)
1.
最难懂的两行代码
c++ auto word = s.substr(j - m * w, w); wd[word] --; if(wd[word] < tot[word]) cnt --;
c++ auto word = s.substr(j, w); wd[word] ++; if(wd[word] <= tot[word]) cnt ++;这两句代码的意思是
1.当滑动窗口的长的
>=i + m * w的时候我们就需要把开头的元素删去当我们的wd[word] < tot[word]的时候说明我们删去的是一个有效的单词,cnt– 2.加入一个word单词当
wd[word] <= tot[word]说明我们加入了一个有效的单词cnt++ 这个算法的时间复杂度是O(w * n),因为每次在哈希表中插入一个元素是O(w)
字符串哈希经本人实验过于麻烦
原因:
不能把每个单词的哈希值插入,这样或导致结果不正确,
比如bbb假设哈希值为 2 + 2 + 2 = 6
abc的哈希值为 1 + 2 + 3 = 6 此时字串并不相同,
所以要把所有单词的排列情况的哈希值给算出来,然后遍历一遍所有的哈希值去比较是否相等
2.我们首先存一下每个words中单词的每一种组合哈希值在一个变量中tot[数组](不可用)
然后我们滑动窗口遍历的时候
用一个变量去存储哈希值wd
我们首先删除一个单词
计算一下这个的单词对应的哈希值,然后用wd减去哈希值;
当我们添加一个的单词
计算一下这个单词对应的哈希值,然后用变量加上哈希值,当这个wd == tot在res中加入wd的开始地址
时间复杂度,插入元素计算哈希是O(1)的所以时间复杂度是O(n)
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> res;
if(words.empty()) return res;
int n = s.size(), m = words.size(), w = words[0].size();
unordered_map<string, int> tot;
for (auto word: words) tot[word] ++;
for (int i = 0; i < w; i ++) {
unordered_map<string, int> wd;
int cnt = 0;
for (int j = i; j + w <= n; j += w) {
if(j >= i + m * w) {
auto word = s.substr(j - m * w, w);
wd[word] --;
if(wd[word] < tot[word]) cnt --;
}
auto word = s.substr(j, w);
wd[word] ++;
if(wd[word] <= tot[word]) cnt ++;
if(cnt == m) res.push_back(j - (m - 1) * w);
}
}
return res;
}
};
