
树上信息的处理
我们拿到树的问题的时候,它们的画风通常都是这个样子的:
- 给定一颗 $n$ 个点的边带权无根树,给出 $m$ 个询问,对于第 $i$ 个询问,你需要求从 $s_i$ 出发到 $t_i$ 终止的最短路径上面的一些信息。
更特殊地,比如下面这个问题:
- 给定一颗 $n$ 个点的边带权无根树,给出 $m$ 个询问,对于第 $i$ 个询问,你需要求 $s_i$ 到 $t_i$ 的最短路径的长度。
要求越快越好。
首先显然直接最短路径只有一条。
因为没有根,我们定 $1$ 作为根会方便一些。
有了根之后,我们就有了每个点到根的距离 $\operatorname{dist}[u]$
我们看一下 $(u, v)$ 两点之间的路径是怎样的:
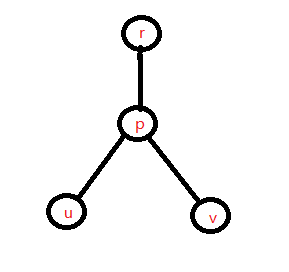
容易发现,$u$ 到 $v$ 的距离就是 $\operatorname{dist}[u] + \operatorname{dist}[v] - 2 \times \operatorname{dist}[p]$,其中 $p$ 是 $u$ 和 $v$ 的最近公共祖先。
那么我们只需要求出 $\operatorname{lca}(u, v)$ 就几乎解决完问题了。
最近公共祖先
关于 $\operatorname{LCA}$,有几种常用的算法:
- 倍增
- $\operatorname{tarjan}$
- 轻重链剖分
LCA:倍增法
我们记一个点的 $k$ 级祖先是它往根节点方向走 $k$ 步得到的节点。
记 fa[i][u] 表示的是点 $u$ 的第 $2^i$ 级祖先。
容易用边 $\operatorname{dfs}$ 边递推的方式计算得到
$$ fa[i][u] = fa[i-1][fa[i-1][u]] $$
处理两个点 $(u, v)$ 的 $\operatorname{LCA}$ 的时候,首先让更深的点跳到两个点相同深度的位置,然后用类似二分的方式,如果 fa[k][u] = fa[k][v] 说明 $f[k][u]$ 是 $\operatorname{LCA}$ 的祖先,否则两个点就可以分别跳到 $2^k$ 级祖先。直到父亲是 $\operatorname{LCA}$ 的时候就可以停下来。
需要注意的是,倍增的同时我们也可以维护每个 $2^k$ 长度的段里面的信息,比如“区间点权和”“区间边权和”“区间边权最小值”之类的,都很容易用递推实现。
LCA:tarjan 算法
倍增法是适用于在线询问的,接下来我们来讲一个离线的 $\operatorname{LCA}$ 做法,它的复杂度比倍增更加优秀。
什么是在线离线?
- 所有询问,你必须依次回答前一个询问,才能进行下一个的,是在线。
你可以将所有询问存储下来,按照自己喜欢的顺序进行求解的(只要最后输出还是照着原来的顺序),就是离线。
我们现在有 $m$ 个点对的 $\operatorname{LCA}$ 需要一起处理。
我们将每个点对标记在树上,然后进行 $\operatorname{dfs}$
我们观察一下点对 $(u, v)$ 的 $\operatorname{LCA}$ 点 $p$ 在 $\operatorname{dfs}$ 时的性质
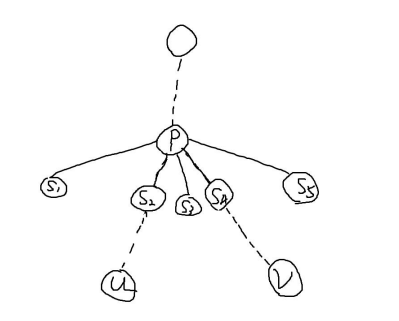
现在我们已经对 $S_1, S_2, S_3$ 回溯完了,准备从 $S_4$ 继续 $\operatorname{dfs}$ 。
我们如果记 f[x] 表示点 $x$ 当前回溯时所碰到的最浅的祖先,容易发现当前 $f[u]$ 恰好为 $p$ 。
现在我们 $\operatorname{dfs}$ 进 $S_4$,找到了点 $v$,而点 $v$ 对应的点 $u$ 已经有了 $f[u]$ 为 $p$,当且仅当这个时候 $p$ 是它们的 $\operatorname{LCA}$ 。
为什么呢?
我们很容易发现一个事实:如果要访问点 $v$ 的时候其对应点 $u$ 的 $f[u]$ 值存在,那么 $f[u]$ 必然是点 $p$,即 $\operatorname{LCA}$。
在这个时候,点 $p$ 尚未往上回溯,因此 $f[u]$ 只能是点 $p$;
另一方面,也不可能在 $f[u]$ 还是 $p$ 的后代时就访问到了点 $v$,因为还没有回溯上来去 $\operatorname{dfs}$ 子树 $S_4$ 。
如果再往上走显然点 $u, v$ 早已被访问过,已经不会再处理了。
这样我们就可以计算出点 $(u, v)$ 的 $\operatorname{LCA}$ 。
我们来整理一下 $\operatorname{tarjan}$ 算法的流程。
首先我们读入所有询问点对,然后对树上每个点都挂一个链表,将询问点对的另一个点给塞进去。初始时所有点的 $f$ 都为自己(也可以设为 $0$)。
然后我们开始 $\operatorname{dfs}$,在回溯过程中我们用一个并查集维护 $f[u]$,我们在回溯的时候将子树的并查集合并到当前子树中,实际上我们相当于是维护一个点集内深度最小的点,用并查集也很容易解决。
接着我们处理当前 $\operatorname{dfs}$ 的这个点所含有的询问,遍历它的链表里的所有点,然后看它们的 $f$ 是否有值,如果有,就将这个值记为答案。
一遍 $\operatorname{dfs}$ 下来,我们就求到了所有询问点对的 $\operatorname{LCA}$ 。
时间复杂度 $O((n+m)\alpha(n+m))$
轻重链剖分/树链剖分
常用的求 $\operatorname{LCA}$ 的方法还有第三种,这种算法也是在线算法,但是它的实用性和可扩展性比前两种要强很多很多。
这其实是一个很体现中国传统封建思想的算法。
它基于这么一个思想:我一个点,有这么多个儿子,总得选一个最牛逼的儿子出来继承家业吧?
我们对每个点 $u$,在它的儿子中选择一个子树大小最大的儿子,作为它的重儿子,记作 $son[u]$,其他的儿子就是轻儿子。
如果我们将树看作家谱,会发现 $u$ 和 $son[u]$ 和 $son[son[u]] \cdots\cdots$ 连起来构成了一支在家族中举足轻重的血缘。
我们将每个点到它重儿子的边叫重边,到轻儿子的边叫做轻边。
由重边组成的链叫做重链,轻边组成的链叫做轻链。
看下面这个例子:
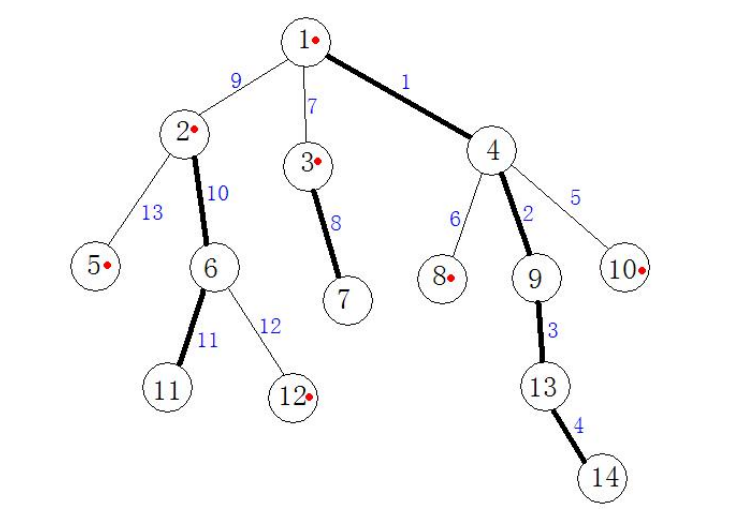
如果我们的树更大一点,有一个重要结论会非常直观:
任何一个点到根的路径上所经过的轻链和重链的数量都是 $O(\log n)$ 级别的。
这个结论等价于,如果我们记 top[x] 表示 $x$ 所属的重链的顶端,fa[x] 表示 $x$ 的父亲,那么我们不断地轮流跳 $top[x]$ 和 $fa[x]$,只需要跳 $O(\log n)$ 次就可以跳到根。
为什么会这样呢?
轻链:明明是我先来得,为什么是跳父亲而不是先跳我呢?
因为重链和轻链都是交叉的,我们实际上只需要考虑轻链的条数。
我们考虑一条边 $(f, v)$,其中 $f$ 是父亲,$v$ 是 $f$ 的轻儿子,我们从 $v$ 跳到了 $f$。
为什么 $v$ 是 $f$ 的轻儿子呢?
显然是因为 $f$ 有一个重儿子 $u$,明明是它子树更大的,当然 $u$ 才是重儿子而 $v$ 不是了。
这里蕴含着一个大小关系:我们记 size[x] 表示点 $x$ 的子树大小,那么 $size[u] \geqslant size[v]$
也就是说,我们从 $v$ 跳到 $f$ 的时候,当前子树大小至少翻了一倍。
换句话说,我们每跳一次轻链,当前子树大小至少翻了一倍。
整个树大小只有 $n$,我们最多只能翻倍 $O(\log n)$ 次,因此只能跳 $O(\log n)$ 次轻链。
有了这个结论之后,我们从某个点往上跳到根就很方便了。
可是我要跳到 $\operatorname{LCA}$ 而不是跳到根,怎么办?
我们仍然利用轻重链来跳。
现在考虑求点 $(u, v)$ 的 $\operatorname{LCA}$
如果 $(u, v)$ 已经处于同一条重链上,那么显然它们深度更浅的那个一定是 $\operatorname{LCA}$ 。
否则,我们取 $top[u]$ 和 $top[v]$ 中深度更深的那个,不妨设为 $top[u]$,我们让 $u$ 跳到 $fa[top[u]]$,也就是一次性跳一条重链+一条轻链。
这样操作后,我们可以保证 $u$ 不会跳到 $\operatorname{LCA}$ 的上面,最多只会和 $v$ 跳到同一条重链。
不断进行这两个判断和操作,最终一定会跳到同一条重链上,然后就停止了。
整理一下树链剖分求 $\operatorname{LCA}$ 的过程:
首先预处理出每个子树的大小和每个节点的深度,并对每个点选择子树大小最大的儿子作为重儿子,然后顺着重儿子 $\operatorname{dfs}$,把重链顶点标记到每个点上。
接着求 $\operatorname{LCA}$ 的时候,就从两个点选 $dep[top[x]]$ 更大的,跳到 $fa[top[x]]$,直到两个点都在同一条重链上(即 $top[x]$ 相等)
这样我们就在 $O(n)$ 预处理的情况下,$O(\log n)$ 地在线回答了 $\operatorname{LCA}$ 问题,并且常数因子非常小,比倍增的要小很多。
树链剖分是半个 $\log$ 的!!!